Research: AI vs. CTFs
⚠️ Disclaimer
Tout ce qui est décrit dans cet article a fonctionné lors de la 5ème édition de Hack'In, le 11 avril 2026. Ce jour-là, avec ce panel de modèles (Claude Sonnet 4.6 / Opus 4.6 — avec et sans extended thinking, GPT-5, Gemini 2.5 Thinking, etc.), avec ces capacités agentiques, avec cette taille de fenêtre de contexte, on a réussi à proposer un CTF qui restait intéressant et difficile même pour les équipes qui spammaient l'IA.
Cependant : ce qui marche aujourd'hui ne marchera probablement plus dans 6 mois. Les modèles progressent vite, les agents deviennent meilleurs à gérer le contexte long, à lancer des outils, à itérer. La majorité des techniques décrites ici exploitent des limites actuelles des LLMs : la pollution de contexte qui les fait diverger, le manque de training data sur des challenges qui sortent du lot, les biais d'attention sur les premières/dernières instructions au détriment du milieu, etc.
Tout ça, c'est une photo à un instant T. Le but de cet article n'est pas de donner la recette ultime du CTF AI-proof. C'est de partager une approche, des heuristiques, et surtout la mentalité qu'on a adoptée : on n'essaie pas de bloquer l'IA, on essaie de garder le challenge intéressant même avec elle.
Si vous lisez ça en 2027 et que les techniques ne fonctionnent plus, c'est normal. Adaptez.
NB : Cet article est centré sur la partie technique « anti-AI ». Le retex complet de l'édition (orga, communauté, ce qu'on a appris en tant qu'équipe) viendra dans un article séparé, après l'event Hack'In 5ème édition.
L'état des lieux fin 2025 / début 2026
Avant d'attaquer le sujet, un petit panorama sourcé. Sans ce contexte, cet article ressemble à un caprice. Depuis 18 mois, le monde du CTF traverse une crise existentielle à cause des LLMs, et ce qu'on a fait à Hack'In s'inscrit là-dedans — on n'est pas partis de rien, on est partis de la conviction que la communauté s'était posée la mauvaise question.
Pour donner une mesure quantitative de la crise : Jacob Krell (Suzu Labs) a analysé les first blood times de 423 machines Hack The Box sorties entre mars 2017 et octobre 2025. Conclusion : les root blood times déclinent d'environ 16% par an en log-space, avec une accélération marquée après l'arrivée des LLMs et des frameworks d'exploitation agentiques (Security Boulevard, mars 2026). Concrètement, en projetant la courbe : ce qui prenait 8h à un top hacker en 2020 se fait en environ 3h aujourd'hui, avec un coude marqué post-2023.
Le drame BSidesSF 2026 — l'événement qui a fait imploser le débat
Édition mythique, organisateurs reconnus, public technique. Résultat de la compétition d'avril 2026, tel que documenté par Include Security dans son post « CTFs in the AI Era » :
- 16 équipes ont solve TOUS les challenges
- Aucun challenge n'a eu moins de 25 solves
- Les 10 premières équipes étaient entièrement automatisées — agents Claude Code et Codex
- La majorité des challs étaient flag quelques minutes après leur release
- À part 2-3 OSINT, Claude/Codex pouvait résoudre tous les challs, y compris du crypto et du binary exploitation qui aurait été "unsolved" l'année d'avant
Pour rappel : en 2025, sur le même CTF, l'équipe gagnante était la seule à avoir frôlé le full solve (Include Security, idem). Un an plus tard, full solve + 15 autres équipes derrière. La différence ? L'arrivée des agents.
L'équipe Veria Labs a même publié l'agent qu'ils ont utilisé en open-source (github.com/verialabs/ctf-agent), avec en titre de repo : « Autonomous CTF solver that races multiple AI models in parallel. 1st place BSidesSF 2026 ». C'est devenu une commodity.
Les autres événements qui ont fait du bruit
hxp — décembre 2025. L'un des CTF les plus respectés au monde. La catégorie cryptographie a été décrite comme « autonomously sloppable » — l'IA seule pouvait pondre les solutions (Include Security, avril 2026).
DEF CON CTF Finals 2025 — août. Au moins 2 challenges des finales ont été résolus avec une assistance LLM majeure. Wil Gibbs a documenté sur son blog un de ces solves comme « la première fois que je vois un challenge à ce niveau être bypass via MCP ».
picoCTF 2025. Des évaluations académiques (notamment via SWE-Agent — le framework de Princeton/CMU initialement conçu pour faire résoudre des tâches d'ingénieur logiciel à un agent LLM, repris pour des évals sécurité — et d'autres baselines) ont montré qu'avec 3 essais par challenge, un agent solo solve ~15 challs en autonomie — surtout les easy/medium en reverse, crypto, web et forensic. picoCTF lui-même a publié un post sur l'IA en cybersécurité en septembre 2025 reconnaissant la bascule. Le CTF d'apprentissage le plus connu au monde est devenu un benchmark de LLM.
HTB AI vs Human Challenge — avril 2025. Compétition explicitement opposant 8 équipes d'agents à 403 équipes humaines, sur 20 challs crypto/reverse, 48h, $7 500 de cash prize. 5 des 8 équipes IA ont individuellement solve 19/20 challs (Hack The Box, mai 2025). Les humains n'ont conservé l'avantage que sur le challenge final multi-étapes.
Benchmark HTB / NeuroGrid CTF — mars 2026. 1 078 équipes (120 IA-augmented, 958 humaines), 36 challs sur 9 domaines, 3 jours. Résultats publiés par HTB (rapport benchmark, mars 2026) :
- Solve rate : 27% côté IA-augmented vs 16% côté humains-only (top teams)
- Gain de productivité 3-4x pour les équipes « elite augmented »
- Pic d'avantage IA sur la difficulté moyenne (3,89x), retombe à 2,97x sur le hard
- Plus de 70% d'amélioration du solve rate à fenêtre de temps égale
Le ras-le-bol des organisateurs et de la communauté
Au-delà des chiffres, c'est un ras-le-bol massif qui traverse la communauté, et il est de plus en plus public. Trois angles différents qui valent la peine d'être lus en entier :
Le constat structurel — Krell (Suzu Labs / Security Boulevard). Pour Jacob Krell (« The Death of the CTF: How Agentic AI Is Reshaping Competitive Hacking », mars 2026), les agents ont des avantages structurels que les humains ne rattraperont pas : parsing d'output sans erreur, accès à tout le corpus public de recherche en vuln, synthèse multi-source sans fatigue cognitive, pas de limite de mémoire de travail. Sa conclusion vise les recruteurs : un top-100 HTB en 2026, ça peut refléter des skills d'exploit manuelle… ou refléter que le candidat a juste un bon pipeline agentique. Le leaderboard a perdu son sens en tant que proxy.
La perte de l'âme du CTF — k3ng. Le post « CTF is dead* » capture mieux que tout autre l'angle « émotionnel ». Pour k3ng, le problème n'est pas le nombre de CTFs (il y en a toujours plus), c'est ce qu'il s'y passe. Les leaderboards sont pleins de full-solves, mais il n'y a plus de discussion après la compétition : les writeups sont devenus des « collections of AI-style solve scripts », et quand l'IA « slops through » tous les challs, il n'y a plus rien à raconter. Le CTF historique reposait sur la curiosité, les unintended solutions, le partage d'expérience — tout ça s'est tu.
Le grief des joueurs — r/securityCTF. Le thread Reddit « CTFs are dead and we killed them » est le miroir côté participants du post de k3ng. Le titre dit tout : la communauté pointe du doigt le fait que ce sont les joueurs eux-mêmes qui ont normalisé l'usage agentique au point que le format ne tient plus.
Les prises de position individuelles. Sur X aussi, des organisateurs et joueurs ont publiquement claqué la porte ou exprimé leur lassitude. Voir notamment @_mixy1 et @Fried_rice — des prises de parole qui circulent largement dans le milieu et reflètent une frustration partagée.
Côté réactions concrètes des orga depuis fin 2025 (voir Include Security pour le tour d'horizon) :
- Certains interdisent l'IA dans le règlement (invérifiable, mais affichage de principe)
- D'autres ont créé des catégories séparées « AI-allowed / AI-forbidden »
- D'autres encore ont basculé en invite-only ou on-site only pour limiter le passage à l'échelle agentique
- Et beaucoup de petits orga ont simplement arrêté, las de voir 6 mois de prep dégommés en 30 minutes
Le sentiment général, début 2026, c'est que personne n'a vraiment réussi à faire un CTF grand public qui reste intéressant en open-AI sur le long format. Soit on bannit (et on ferme les yeux), soit on regarde sa compétition se faire automatiser.
Pourquoi cet article
C'est là qu'on intervient. Hack'In 5ème édition était notre tentative de prouver qu'il existe une troisième voie : assumer l'IA comme variable d'environnement, et concevoir contre. Pas l'interdire, pas séparer, pas abandonner. Juste designer mieux.
Le 11 avril 2026, sur 130 participants en open-AI complet, on a tenu 12h sans que la compétition tombe. 5 équipes seulement ont solve plus de la moitié des challs, et le feedback satisfaction est ressorti à 4,2/5 côté AI comme côté no-AI. C'est pas BSidesSF 2026 (pas la même échelle), mais sur le format open-AI, c'est ce qui se rapproche le plus d'une preuve qu'on peut encore designer pour les humains en 2026.
C'est pas une recette miracle (cf. disclaimer). C'est un retex. La suite de l'article détaille comment.
Pour creuser le sujet
Si vous voulez le contexte complet avant de lire la suite :
- Krell, Jacob. « The Death of the CTF: How Agentic AI Is Reshaping Competitive Hacking ». Security Boulevard / Suzu Labs, mars 2026. — l'analyse quantitative la plus solide du moment.
- Include Security Research Blog. « CTFs in the AI Era ». Avril 2026. — le retex BSidesSF 2026.
- k3ng. « CTF is dead* ». — la perte du tissu communautaire derrière les leaderboards.
- r/securityCTF. « CTFs are dead and we killed them ». — la version côté joueurs.
- Gibbs, Wil. « All You Need Is MCP — LLMs Solving a DEF CON CTF Finals Challenge ». — un des premiers solves majeurs assistés par MCP en CTF top-tier.
- Hack The Box. « AI vs Human: CTF results show AI agents can rival top hackers » (mai 2025) et « HTB Benchmark Report » (mars 2026). — les deux benchmarks chiffrés.
- picoCTF. « What I Wish More People Knew About AI in Cybersecurity ». Septembre 2025.
- @_mixy1 sur X, @Fried_rice sur X. — deux prises de position individuelles dans la communauté.
- Veria Labs.
ctf-agent. — le repo open-source du gagnant BSidesSF 2026.
Contexte — pourquoi se poser la question
Pour la 5ème édition de Hack'In, on a voulu monter le niveau encore d'un cran. Sur les 4 éditions précédentes on était sur du « beginners friendly », plein de challs faciles pour donner envie de continuer. Cela fait depuis l'année dernière que l'on essaie de fournir une compétition plus « exclusive ».
Le format final :
- 48 challenges
- 15 catégories
- 12 heures de CTF (soit ~3 sessions Claude pour ceux qui paient le plan max)
- 0 restriction sur l'usage de l'IA
- 1 promesse : que la compétition reste intéressante, même avec l'IA
La restriction de l'usage de l'IA en compétition est un sujet vraiment TRÈS chaud dans la communauté depuis 2025. On aurait pu interdire l'IA dans le règlement. Sauf que :
- C'est invérifiable (on ne va pas regarder par-dessus l'épaule de 50 équipes)
- C'est anachronique : en 2026 plus personne ne fait de cyber sans IA, pas plus que personne ne code sans Stack Overflow en 2010
- C'est paresseux : ça reporte le problème de design sur le règlement
Donc on part dans l'autre sens : on assume que toutes les équipes utilisent Claude/GPT/Gemini en mode agentique, et on conçoit les challs en partant de ça.
Notre position
Avant de plonger dans la technique, il faut bien fixer le cadre :
Le but n'est PAS d'empêcher l'IA de résoudre les challenges. Le but est de faire des challenges qui restent intéressants avec ET sans IA.
C'est une nuance importante. Un chall qui prend 30 secondes à un humain et 5 secondes à l'IA, c'est nul. Un chall qu'aucune IA ne peut résoudre mais qu'aucun humain non plus, c'est nul aussi. Le sweet spot c'est :
- Un humain seul peut le résoudre s'il comprend le sujet
- Une IA seule galère sans guidage humain
- Un humain + IA est plus rapide qu'un humain seul, mais pas infiniment
L'IA doit rester un outil, pas un remplaçant. Si le solve devient juste « copier l'énoncé dans Claude et coller la réponse », on a perdu.
Comprendre « l'IA »
Avant de toucher à un seul chall, on a passé du temps à comprendre comment fonctionnent les LLMs et surtout comment ils sont utilisés en contexte CTF. Cette section est volontairement vulgarisée — l'idée c'est que même si vous n'avez jamais ouvert un papier sur les transformers, vous compreniez pourquoi les techniques qui suivent fonctionnent.
Petit aparté : comment fonctionne un LLM (TL;DR)
Trois trucs à intégrer pour la suite :
1. Tout est token. Quand vous envoyez un prompt à Claude, le texte est d'abord découpé en « tokens » (en gros, des morceaux de mots). Le modèle ne voit pas du texte, il voit une suite d'identifiants numériques. Une session avec 100k tokens chargés, c'est l'équivalent de ~75 000 mots de contexte.
2. Le modèle prédit le token suivant. À chaque étape, le LLM regarde tout le contexte (system prompt + conversation + sa propre génération en cours) et calcule la distribution de probabilité du token à venir. Il n'a pas de « pensée séparée » du flux de tokens, tout passe par cette boucle de prédiction autoregressive.
3. L'attention coûte cher et se dilue. Le mécanisme central des transformers, c'est l'auto-attention : chaque token regarde tous les autres pour décider de quoi est important. Le coût mémoire/compute est en O(n²) sur la taille du contexte — en théorie. En pratique, les implémentations 2026 (FlashAttention-3, sliding window, ring attention, sparse attention) atténuent fortement ce coût. Mais le phénomène de dilution de l'attention demeure : plus le contexte est long, plus l'attention disponible « par token utile » diminue. Ce n'est pas seulement « le modèle a plus à lire » — c'est qu'il devient statistiquement moins capable de pondérer correctement ce qui compte.
C'est ce dernier point qui est le vrai levier. Quand on parle de « pollution de contexte », on parle de cette dilution de l'attention.
Trois biais cognitifs des LLMs qu'il faut connaître
Ces trois biais sont documentés académiquement et c'est précisément ce qu'on a exploité dans le design des challs.
Primacy effect. Les LLMs accordent une attention disproportionnée aux premiers tokens du contexte. Empiriquement, c'est généralement là que vivent le system prompt, les instructions générales, la consigne du user. Modifier le début d'un prompt a beaucoup plus d'impact comportemental que modifier le milieu — c'est aussi pour ça que les jailbreaks « par préfixe » fonctionnent bien.
Recency bias. Symétriquement, les tokens les plus récents ont une influence forte sur la prédiction. C'est ce qui permet à Claude de répondre à votre dernière question plutôt qu'à celle d'il y a 10 messages. Dans un agent, c'est aussi la raison pour laquelle un dernier tool output bizarre peut totalement faire dériver le plan de résolution.
Lost in the Middle. Le creux entre les deux. Liu et al. (2023, « Lost in the Middle: How Language Models Use Long Contexts », arxiv:2307.03172) ont mis en évidence une courbe en U sur des tâches de retrieval : un modèle retrouve très bien une info placée en début ou en fin de contexte, mais ses performances chutent drastiquement quand l'info est posée au milieu. Le papier d'origine testait jusqu'à 16k de contexte ; le phénomène a été reproduit depuis sur des fenêtres plus longues, avec des variantes selon les architectures.
Important pour le 2026 : les modèles frontière (Claude 4.6, GPT-5, Gemini 2.5) ont été spécifiquement entraînés contre ce biais via des benchmarks « needle-in-a-haystack », du long-context fine-tuning, et des architectures hybrides. Le phénomène persiste, mais s'est significativement atténué. C'est précisément l'une des raisons pour lesquelles cette technique aura une durée de vie limitée — chaque génération suivante encaisse mieux les contextes longs.
Concrètement pour nous : si une info est posée au début (la description du chall) ou vient juste d'arriver (le dernier tool output), l'IA la prend en compte. Si elle est noyée au milieu d'une conversation longue avec 30 itérations d'outils et 50k tokens de logs, elle peut littéralement disparaître de la « mémoire active » du modèle.
C'est ce qui rend toutes nos techniques exploitables.
Le knowledge cutoff
Détail crucial qu'on va exploiter abondamment : un LLM est entraîné sur un corpus figé à un moment donné. Cette knowledge cutoff est généralement comprise entre 6 et 18 mois avant le déploiement du modèle (Claude Opus 4.6 a une cutoff Mai et Aout 2025, par exemple et Opus 4.7 en janvier 2026).
Tout ce qui a été publié après la cutoff — CVE, writeups, papers, code OSS — n'est pas dans les poids du modèle. L'IA peut éventuellement le récupérer via web search ou dans le contexte qu'on lui fournit, mais elle n'a aucune intuition statistique dessus. Sur les sujets pré-cutoff, un modèle est imbattable. Sur les sujets post-cutoff, il est juste correct comme un humain l'aurait été en lisant le sujet pour la première fois — voire moins bon, parce qu'il a moins d'expérience pour combler les blancs et qu'il a tendance à pattern-matcher de force sur ce qu'il connaît.
C'est l'unique fondement structurel de notre Technique #1 (les 0-days).
Note sur les modèles à raisonnement (extended thinking)
Les modèles 2026 ont tous une capacité supplémentaire qu'on a explicitement intégrée à notre étude : le mode extended thinking (ou reasoning mode). Claude 4.6 avec un budget de thinking, GPT-5, Gemini 2.5 Thinking peuvent délibérer en interne avant de répondre — ils génèrent silencieusement des centaines à des milliers de tokens de raisonnement avant la sortie, ce qui leur permet de planifier, de s'auto-critiquer, et de revenir sur leurs choix.
En théorie, ces modèles devraient être beaucoup plus résistants à nos techniques :
- Ils détectent mieux les fausses pistes (Technique #2)
- Ils sont moins susceptibles de « confirmer » un bad finding sans vérifier (Technique #3)
- Ils planifient les exploits longs au lieu de les exécuter en réflexe (Technique #4)
- Ils relativisent mieux les descriptions trompeuses (Technique #5)
En pratique, ils performaient effectivement mieux que les modes non-thinking. Mais pas assez pour invalider nos techniques :
- Le thinking budget reste fini, et il consomme énormément de tokens en sortie — donc accélère encore l'épuisement du plan utilisateur
- Le raisonnement interne est lui-même soumis au lost in the middle et au primacy effect, parce que c'est généré dans la même fenêtre
- Il ne corrige pas le primacy effect quand l'utilisateur copie-colle la description trompeuse en direct sans laisser le modèle questionner
- Sur les pièges « rapport au temps » (Technique #4), le thinking ne change rien : l'humain est toujours impatient
Cela dit, c'est exactement le type de capacité qui rendra cet article obsolète. Les modes raisonnement progressent vite, la tendance montre une réduction continue des biais qu'on exploite.
Côté IA, ce qui compte en compétition
| Levier | Explication |
|---|---|
| Le prompt | Plus il est précis, plus l'IA va vite. Si l'énoncé est ambigu ou bruité, l'IA part dans tous les sens (cf. primacy effect : la description initiale pèse lourd) |
| La fenêtre de contexte | Sonnet 4.6 / Opus 4.6 : 200k tokens en standard, jusqu'à 1M sur les endpoints dédiés. Une fois saturée, le modèle oublie ou diverge — et bien avant la saturation, le « lost in the middle » dégrade déjà la qualité |
| La génération token-par-token | L'IA prédit le token suivant en fonction du contexte. Plus elle a vu de patterns similaires en training, plus elle est efficace |
| Le coût en tokens d'une exploration | Chaque tool call, chaque output volumineux pèse. Une grosse codebase à analyser épuise le budget |
| Les capacités agentiques | Claude Code / Cursor peuvent exécuter du code, scanner, itérer. Mais ils restent limités par le contexte et la durée d'une session |
| L'éthique et les guardrails | Les modèles peuvent refuser certaines actions (RCE explicites, exfiltration, etc.) |
Côté humain, ce qui compte aussi
L'humain qui pilote l'IA a ses propres faiblesses qu'on peut exploiter :
- L'attente : un humain qui attend 3 minutes devant un prompt va perdre patience
- La frustration : 4 essais qui échouent et l'utilisateur va reset la session, perdre tout le contexte
- Le workflow : la plupart des gens font « copier l'énoncé → demander à Claude → essayer la réponse ». C'est exploitable
- La distribution de difficulté : plus on a de challenges faciles, plus ça sera une compétition IA-friendly
Il faut garder en tête que ce qui va différencier un humain de la machine, ça va être son rapport au temps et ses émotions.
Notre objectif
Notre objectif est de trouver la bonne recette pour récompenser les joueurs qui utilisent l'IA en comprenant les challenges et de punir ceux qui balancent des agents random sans comprendre. On va donc jouer sur trois ressources clés :
- Contexte : plus le contexte est gros, plus l'attention se dilue, plus le modèle est moins pertinent → on veut le remplir.
- Token : c'est le graal. Une fois qu'il n'y a plus de tokens (limite de session, plan payant épuisé, fenêtre saturée), on force l'utilisateur à remettre les mains dans le cambouis → il faut en consommer un maximum.
- Patience : personne n'aime attendre devant un prompt → on veut forcer l'utilisateur à se demander « pourquoi le modèle galère » et l'obliger à comprendre le challenge pour le débloquer.
En consommant du contexte, des tokens et de la patience humaine, on force le participant à se dire « bon, je regarde ce qu'il se passe ».
Et pour ça on va utiliser :
- Les workflows des gens qui balancent l'IA dans tous les sens
- Le mode de fonctionnement des LLMs en lui-même (les trois biais ci-dessus)
- L'argent limité (on espère) des participants — un plan API ou une session premium, c'est pas illimité
Technique #1 — « The most technical CTF »
L'idée
Aucun challenge facile. Que des challs « insane » au sens propre. Si on ne peut pas faire un chall difficile sur un sujet, on le sort en physique ou avec social engineering.
Concrètement, sur les 48 challs proposés :
- 0 challenge classé "easy"
- Une part importante basée sur des 0-days qu'on a trouvés en interne au cours des 6 mois précédents
- Plusieurs challs basés sur de la recherche maison (cf. certains articles sur ce blog)
- Les sujets « classiques » (XSS, SQLi, LFI...) ont été remplacés par des variantes peu documentées
Pourquoi ça marche contre l'IA
Un LLM est entraîné sur le passé. Toutes les CVE, toutes les box de HackTheBox publiques, tous les writeups CTF, tout le code OSS public — il l'a vu jusqu'à sa knowledge cutoff (généralement 6 à 18 mois avant son déploiement), souvent plusieurs fois. Sur ces sujets-là, il a un avantage massif : il pondra l'exploit instantanément, souvent avant même qu'un humain ait fini de lire l'énoncé.
Mais sur un 0-day non publié (donc post-cutoff par définition), l'IA n'a aucune intuition statistique exploitable. Elle va devoir :
- Charger toute la codebase (= cramer du contexte)
- Comprendre l'architecture (= cramer du contexte)
- Identifier des sinks potentiels par raisonnement abstrait (= cramer du contexte ET hallucinations possibles)
- Tenter des exploits qui ne marchent pas → corriger → réessayer (= cramer du contexte ET perte de patience humaine)
- À chaque erreur le tool output revient dans le contexte et bouffe encore du budget
Exemple concret : la 0-day caméra
Un de nos challs s'appuyait sur un 0-day que @spikiky avait trouvé sur le firmware d'une caméra IP.
Toute la partie reverse a cramé beaucoup de tokens (qui ne peuvent donc plus être utilisés sur d'autres challenges). Ensuite l'exploitation se faisait physiquement via une borne wifi sans internet : plus personne n'utilisait l'IA en mode agentic à ce moment-là. Enfin, il ne suffisait pas juste de « pwn » la caméra (ce qui est un flow connu en CTF) : il fallait réussir à comprendre le fonctionnement propriétaire du firmware pour pouvoir prendre une photo complète et non pas partielle. Dans un contexte de CTF, ce n'est pas une problématique qu'on a l'habitude de voir. Et donc faire « cracher » la bonne solution à un modèle allait demander la consommation de beaucoup de tokens, surtout que le firmware est propriétaire et donc avec un training limité dessus.
À noter aussi que c'est cohérent avec le benchmark HTB de mars 2026 : l'avantage relatif de l'IA pique sur la difficulté moyenne (3,89x) et retombe à 2,97x sur le hard. Concevoir uniquement des challs hard/insane, c'est aussi prendre l'IA exactement là où son avantage relatif est le plus faible.
Takeaway #1 : plus le sujet est récent, privé et avec peu de data, plus l'IA est handicapée. La 0-day est une arme ultime car on charge beaucoup de contexte ; mais si la vulnérabilité est juste une vuln de CTF easy, elle se fera quand même résoudre vite.
Technique #2 — Context pollution
L'idée
Inonder le challenge de bruit pertinent qui force l'IA à charger plus de contexte qu'elle n'en a besoin, et qui la pousse à explorer des fausses pistes.
Pour rappel : plus le contexte est plein, plus l'auto-attention se dilue, et plus le « lost in the middle » fait son travail. La vraie info utile finit noyée entre 5000 lignes de bruit et le modèle, au moment de raisonner, ne la pondère plus correctement. C'est ce qu'on appelle communément le context rot.
Comment on pollue, en pratique
- Multiplier les vulnérabilités décoratives — vulns réelles mais qui ne mènent pas au flag.
- Code mort qui ressemble à des sinks actifs — genre une fonction
do_query()qui contient uneval()mais qui n'est jamais appelée. L'IA va passer du temps à essayer de l'atteindre. - Commentaires trompeurs —
// TODO: fix this XSS before prodau-dessus de code qui n'a aucune XSS. - Codebases gigantesques — au lieu d'un chall avec 200 lignes, en mettre 5000. La plupart sans intérêt.
- 0-days en mode « charger le contexte » — un chall qui force à lire un binaire de 50 Mo si on veut comprendre quoi que ce soit.
Exemple : le sink qui n'en est pas un
Sur un chall web, on a mis un endpoint :
@app.route("/admin/exec", methods=["POST"])
@require_admin
def admin_exec():
cmd = request.json.get("command")
# Legacy endpoint - kept for backward compatibility
# TODO: remove after migration #4218
output = subprocess.check_output(cmd, shell=True)
return jsonify({"output": output.decode()})Vulnérable, évident, mais inatteignable : @require_admin valide un JWT signé avec une clé qui n'est pas leak ailleurs dans le chall, et le seul moyen d'avoir un token admin est de résoudre le vrai chall (une chaîne d'erreur logique dans la gestion des sessions, complètement ailleurs).
L'objectif est de pousser le modèle à bypass le JWT (forgery, signature confusion, kid injection, etc.). Le subprocess.check_output(cmd, shell=True) et la mention command dans le request.json sont des patterns saillants : ces motifs ont été massivement étiquetés « dangerous » dans le training data (vulnérabilités OWASP, semgrep rules, audits publics), et l'IA les flag en réflexe. Ça la force à investir son catalogue d'attaques « classiques » sur le JWT pour atteindre ce sink visible. Une fois ces attaques tentées, elle finira par parcourir d'autres options et trouver le vrai sink menant au flag — mais en attendant, on a fait cramer des tokens et du contexte.
Le participant qui réfléchit par lui-même, repère le vrai sink, et demande à son modèle de se concentrer dessus va gagner du temps par rapport à ceux qui auto-solve les challenges.
Petit tip : ajouter des faux sinks qui ont énormément d'attaques connues, dont du bruteforce. Ça poussera le modèle à tenter des attaques via bruteforce qui peuvent être longues, ralentir les joueurs qui ne font que de l'IA, et au passage générer des dizaines de milliers de tokens d'output qui vont enfoncer la vraie info dans le « middle » du contexte. Et on espère forcer le participant à se plonger dans le challenge pour corriger le tir.
Takeaway #2 : un sink propre dans 200 lignes propres se fait flag par n'importe quelle IA en 30 secondes. Le même sink dans 5000 lignes avec 3 fausses pistes bien construites se fait flag aussi mais en demandant plus de temps, de contexte et de token.
Limites
C'est de la defense in depth psychologique, pas une vraie barrière. Une IA mieux conçue (avec un meilleur planning, ou un user qui guide intelligemment) finira par trouver. Mais ça récompense ceux qui l'utilise en se posant des questions et ça fait partie de notre objectif.
Technique #3 — « Play the game of AI »
L'idée
Identifier les sujets sur lesquels l'IA est techniquement ultra compétente et en abuser. C'est-à-dire : elle reconnaît la vulnérabilité instantanément, mais elle l'exploite mal parce que la méthode sur laquelle elle a été entraînée pour ce type de challenge n'est pas celle qui marche dans notre setup. Il faut donc la forcer à diverger de son réflexe par défaut.
Le cas d'école : le boolean blind SQLi
Sur un de nos challs, on a mis un SQLi ultra classique :
$id = $_GET['id'];
$row = $db->query("SELECT * FROM articles WHERE id = $id LIMIT 1")->fetch();
if ($row) {
echo "Article exists";
} else {
echo "Article not found";
}Un humain qui voit ça reconnaît immédiatement : boolean blind SQLi. Tu envoies des conditions, tu observes la différence d'output, tu extrais la donnée bit par bit.
L'IA aussi repère instantanément la vulnérabilité, et elle est surentraînée à produire le script d'exploitation puisque c'est une vuln présente dans quasiment TOUS les CTF — l'espace de probabilité du token suivant est ultra concentré sur les patterns connus (UNION-based, sqlmap, payload classique).
Sauf que le tricks, c'est qu'on avait mis en place un rate-limiting tout bête sur l'application qui empêchait le bruteforce « bête et méchant ».
Comme on l'a dit plus tôt, la machine n'a pas le même rapport au temps que nous. Elle fournit un script d'exploitation qui fonctionne dans l'absolu. Et elle parvient assez vite à obtenir les premiers résultats — ça confirme son finding. Elle est donc persuadée de la justesse de son payload, et cette confirmation, étant un des derniers tokens dans son contexte, va peser lourd sur la suite (recency bias) : elle va continuer à pousser dans la même direction.
Sauf que pour ce challenge-là, sans optimisation, il fallait 30h pour extraire le flag. Avec les optimisations de base, en moins de 40 minutes, le flag tombe.
Pourtant aucune équipe n'a solve ce challenge, pas une seule personne sur 130 participants. Parce qu'il fallait presque « prompt injecter » le modèle pour le forcer à explorer une autre façon de le résoudre.
Le modèle est ultra entraîné sur cette attaque, il sait pondre le script de résolution instantanément, et il a très vite confirmation que le script « marche ». Donc si on ne lui apporte pas une bonne raison d'adapter ou de considérer une alternative, il va continuer à confirmer que c'est la bonne façon de faire.
Cela force l'utilisateur à se pencher sur le challenge, le comprendre, et mieux guider son modèle via son expertise.
Sauf que ce qu'il se passait, c'est que les joueurs perdaient patience, pensaient parfois que le modèle hallucinait, et recommençaient depuis un contexte frais. Pour nous c'est tout bénéf : nouvelle exploration, on crame du token !
Takeaway #3 : repérer les techniques où l'IA est entraînée mais où sa sortie « par défaut » est sous-optimale. Le user devra connaître le sujet pour la corriger, et c'est exactement ce qu'on veut.
Technique #4 — Ce qui sépare l'humain de la machine : le temps
L'idée
Cette technique a souvent été combinée avec d'autres et elle consiste à attendre. Ici on joue sur la patience de l'utilisateur et on espère qu'il va reset, repartir de zéro parce qu'il pense que l'IA fait n'importe quoi ou qu'elle est plantée.
Donc : on conçoit des challs où la résolution efficace nécessite de laisser tourner.
Attention, l'idée ce n'est pas de faire des challs guessy/bruteforce mais qui restent intéressants à résoudre.
Mécaniques exploitables
| Mécanique | Effet |
|---|---|
| Rate limit fort sur un endpoint clé | Force à attendre entre les requêtes |
| Backend lent par design (sleep côté serveur) | Chaque tentative coûte du temps réel |
| Verrou sur un compte après N tentatives | Force la patience |
| Cron job qui ne tourne que toutes les 10 min | Tu attends que ça passe ou tu te débrouilles autrement |
| Dépendance entre challs avec délais imposés | Le chall B nécessite un événement déclenché par A 5 min plus tôt |
Exemple : le SQLi time-based qui force à patienter
Reprenons notre SQLi de la technique 3 et admettons que l'IA a trouvé la bonne optimisation pour résoudre le challenge en une vingtaine de minutes. Pour un humain, vingt minutes c'est long. Et si l'utilisateur n'a pas compris le challenge, il va penser que l'IA hallucine/plante et repartir de zéro — donc encore une fois refaire son contexte, et cramer du token.
Ça force donc l'utilisateur à comprendre le challenge pour saisir que le flag ne sera là que dans 20 minutes. Sur une compétition de 12h, c'est largement acceptable.
De plus on peut ajouter des petites optimisations pour « polluer » le contexte. Par exemple on renvoie une erreur 429 si on dépasse le nombre de requêtes, avec un cooldown qui s'allonge progressivement (1s, 2s, 4s, 8s...).
Pour extraire un mot de passe de 32 caractères en SHA256 → 64 hex chars → ~256 bits → ~256 requêtes en binary search. À 1 req / 2s = ~9 minutes de runtime au minimum.
Une IA agentique qui pilote ça : à chaque requête, elle reçoit un tool output qu'elle remet dans son contexte. 256 requêtes × ~300 tokens en moyenne (request + response + retry-after + narration interne du modèle) = ~77k tokens cramés juste pour le runtime. En jouant sur la verbosité des réponses 429 (un body bien gras, des headers custom), on peut faire grimper jusqu'à 100-150k tokens et saturer la fenêtre avant d'avoir le mot de passe complet. Et au passage, l'instruction initiale (la description du chall) part dans le « middle » du contexte au fur et à mesure que les tool outputs s'accumulent — exactement le scénario où le lost in the middle dégrade le raisonnement du modèle.
Takeaway #4 : le temps est l'une des ressources où sa valeur est "la plus différente" entre un modèle et un humain à cause de nos émotions. Plus une solution est étalée dans le temps, plus elle force le user à comprendre car ça génère de la frustration.
Attention au piège
Il faut doser. Si tout le CTF demande d'attendre 10 min, les humains vont aussi se barrer.
Technique #5 — « Prompt injection » via la description
L'idée
Mettre dans la description du chall un truc délibérément trompeur ou bruyant, pour pousser l'IA dans une mauvaise direction. C'est l'application directe du primacy effect : la description, c'est le tout premier signal que l'IA reçoit, et c'est celui qui va le plus peser sur tout le raisonnement qui suit.
Je ne pensais pas qu'elle serait aussi efficace.
Comment l'IA traite une description
Quand un user dit à Claude « voici l'énoncé du chall, aide-moi », la description tombe en tête de contexte, juste après le system prompt. C'est la position la plus puissante en termes de pondération d'attention. L'IA va y chercher des mots-clés (noms de techniques, d'outils, références à des CVE connues) et orienter sa stratégie de résolution autour de ces ancres. Plus les mots-clés sont saillants, plus l'IA va halluciner des pistes correspondantes.
Si la description contient une référence à sudo, l'IA va passer 5 minutes à enquêter sur des privesc sudo, même si le chall n'a rien à voir. Si elle mentionne « base de données », elle va chercher des SQLi, des fichiers SQLite, des credentials MySQL — y compris s'il n'y a aucune base sur la machine.
Exemple concret
Un de nos challs système mentionnait dans sa description une base de données.
La solution, c'était presque de faire un sudo su avec juste un petit tricks sur le PAM, vraiment rien de compliqué.
Sauf que dans la description, on a mentionné que ce système était le backup d'un ancien site web avec une DB corrompue (ou un truc dans le style).
Les joueurs copient la description + URL de connexion en une seule fois (généralement sans même prendre la catégorie) et attendent.
Pour ce challenge, tout le monde tournait en boucle sur le fameux site web. Alors que dans le challenge il n'y avait rien : c'était vraiment une Debian de base avec la vuln. Pas de service Apache, Nginx, MySQL, pas de fichier SQLite. Et je recevais des messages générés par IA qui me demandaient de donner l'accès à la BDD. Alors que ça n'avait rien à voir — le challenge était d'une facilité IMMENSE par rapport à d'autres qui se sont fait pwn en quelques dizaines de minutes.
Résultat : 0 SOLVE
C'est l'illustration parfaite des biais qu'on évoquait plus haut. L'IA ancre sa stratégie sur la description initiale (primacy) et sur les derniers tool outputs (recency). Au milieu, elle a pourtant pu voir 100 fois que la machine est une Debian vide — mais cette info, noyée entre la description trompeuse en haut et les tool outputs récents en bas, tombe pile dans la zone du lost in the middle. Le modèle continue à raisonner « il y a une DB quelque part » même quand ses propres ps aux, netstat -tulnp, find / -name "*.db" lui crient le contraire.
C'est aussi pour ça que les agents qui résument périodiquement le contexte (« compaction », rolling summary) peuvent partiellement bypass cette technique — ils ramènent l'info utile du middle vers le bottom. Mais en avril 2026, dans la majorité des workflows utilisateurs (Claude.ai web, ChatGPT, Cursor en mode chat), ça reste exploitable.
Takeaway #5 : la description du chall n'est pas neutre. C'est un input texte que l'IA va traiter, donc on peut le designer pour orienter (ou désorienter). À utiliser avec parcimonie : trop de bruit et l'événement devient guessy plutôt que technique.
Côté organisation — un mot rapide
En 2026, faire des challenges résistants à l'IA ne suffit pas. Il faut aussi que l'événement donne envie de jouer avec ou sans leaderboard. Sinon les gens ouvrent Claude et farment les solves.
Plusieurs mécaniques qu'on a mises en place et qui ont bien tourné :
- Bounty mode — quelques challs avec un cash prize aux X premiers solves. Ça concentre l'attention sur les challs durs, ceux qu'on n'a pas réussi à résoudre avec IA.
- Badge — un badge physique qu'on remet en main propre. Petite récompense émotionnelle.
- Sub-rankings — classements parallèles (ex : catégorie avec et sans AI, etc.) pour que tout le monde puisse jouer dans l'arène qui lui convient le mieux.
- Side quests — obtenir le plus de badges possible, troquer les points contre des éléments dans une boutique, etc.
Le détail organisationnel complet sera dans le post Hack'In 5th edition retex.
Est-ce que ça a marché ?
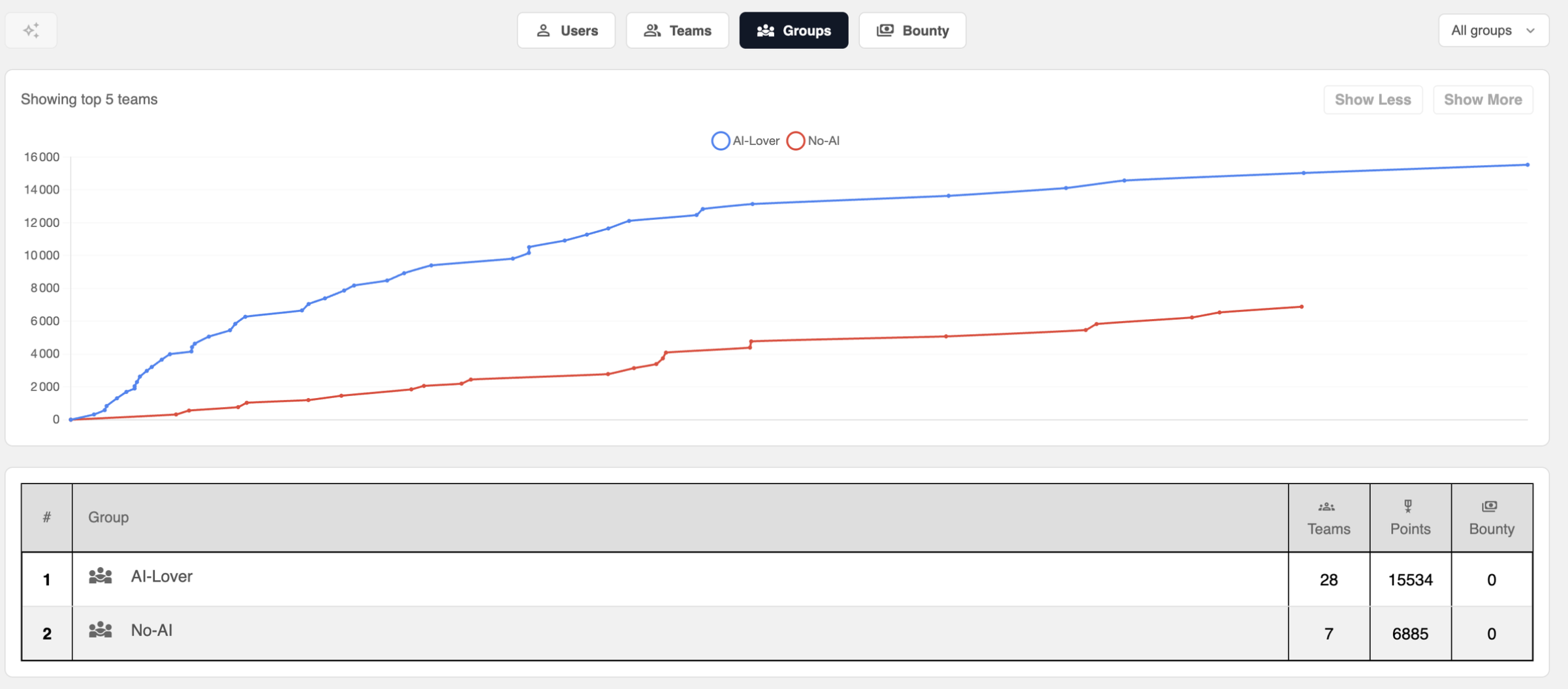
On avait deux groupes représentatifs qu'on a supervisés pendant la compétition :
- Group NO-AI : équipes qui se sont volontairement interdit l'IA (28 teams)
- Group AI-LOVER : équipes qui utilisaient l'IA (7 teams)
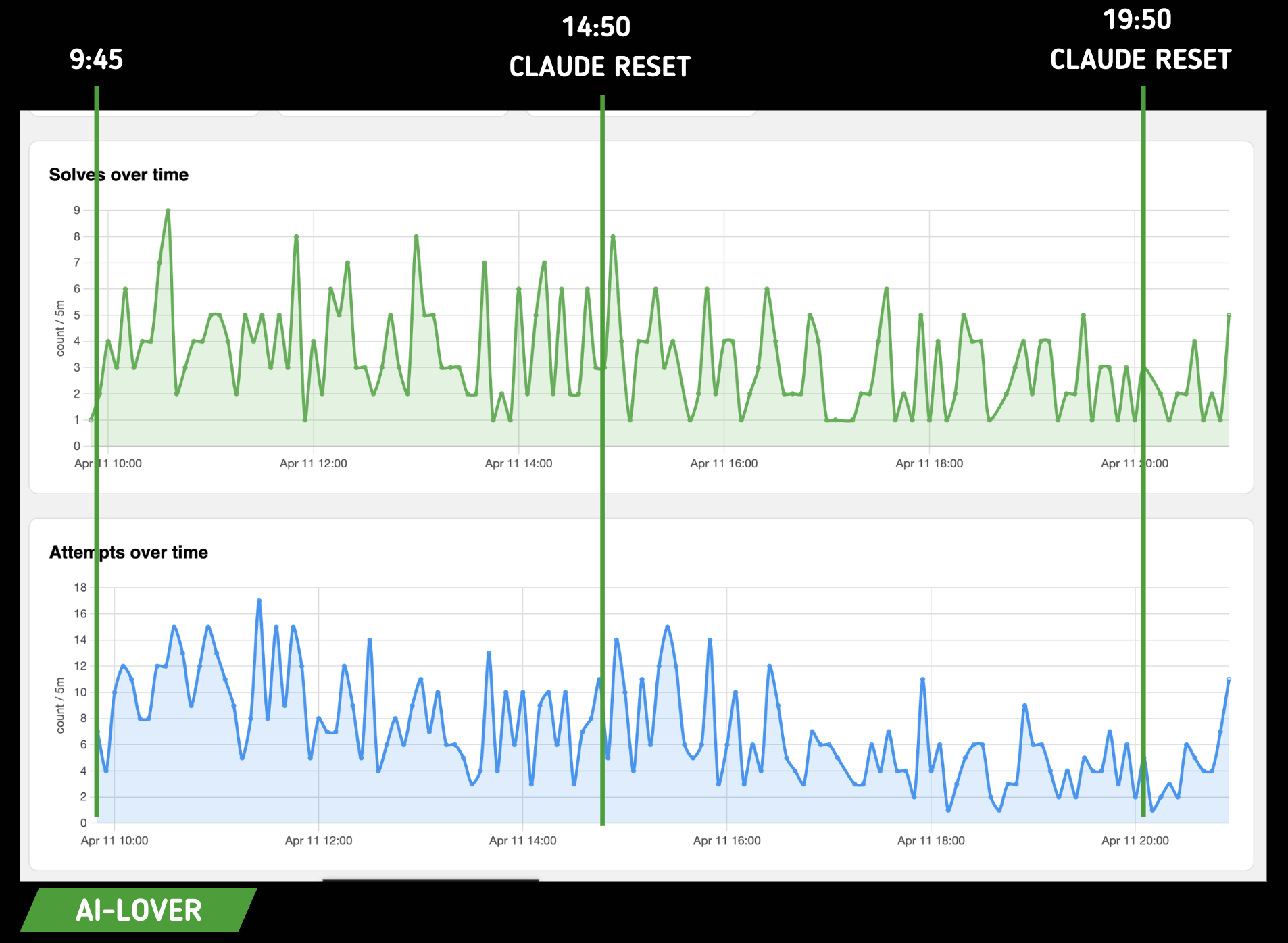
Voici la vitesse de résolution :
Pour la team AI :
Pour la team NO-AI :
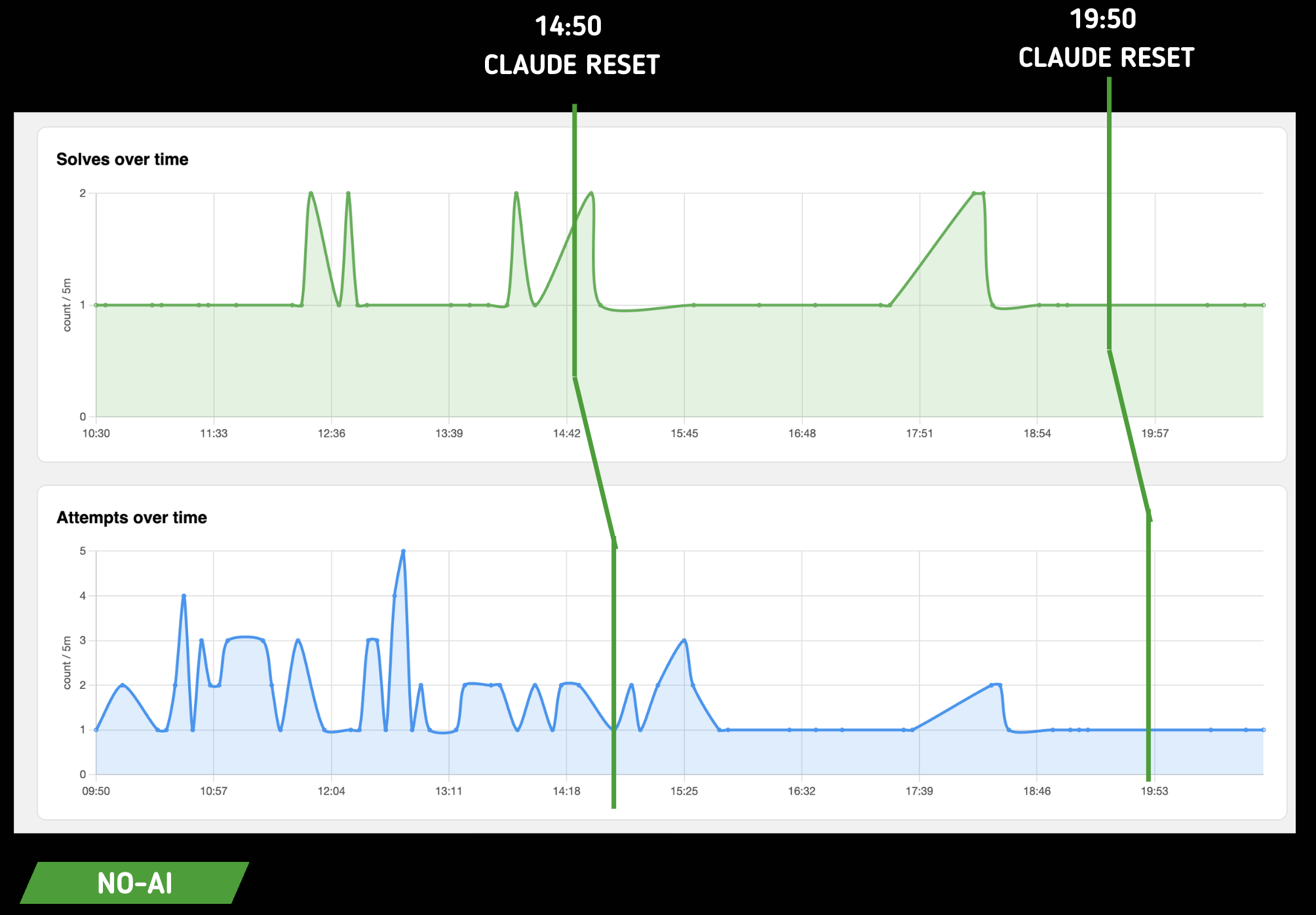
Ici on voit bien que la résolution des challenges n'est pas indexée sur le reset des tokens Claude. Pour nous c'est une bonne nouvelle : ça veut dire qu'il n'y a pas eu de corrélation directe, ou en tout cas flagrante, entre disponibilité de token et facilité de résolution.
Cependant on a remarqué une différence sur la façon de flagger.
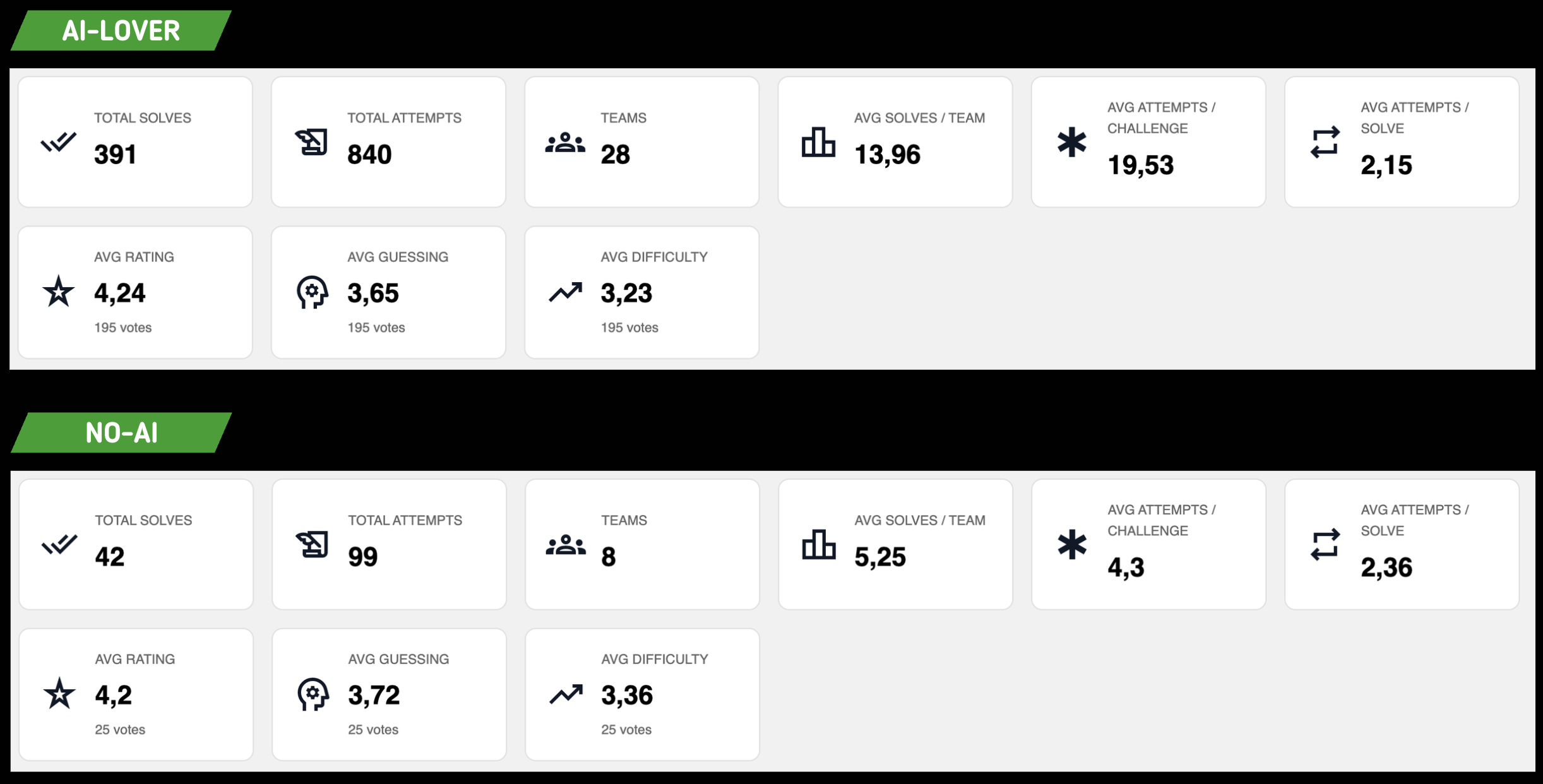
Déjà on voit que la moyenne de résolution de challenge pour les teams avec AI est de 13,96 sur 48 challenges soit 29,08% des challenges ce qui est une IMMENSE victoire pour nous.
On avait peur que notre CTF se fasse plier en une heure, et même après 12h le taux de résolution est resté bas.
Voici sur le top 13 le nombre de challenge résolus
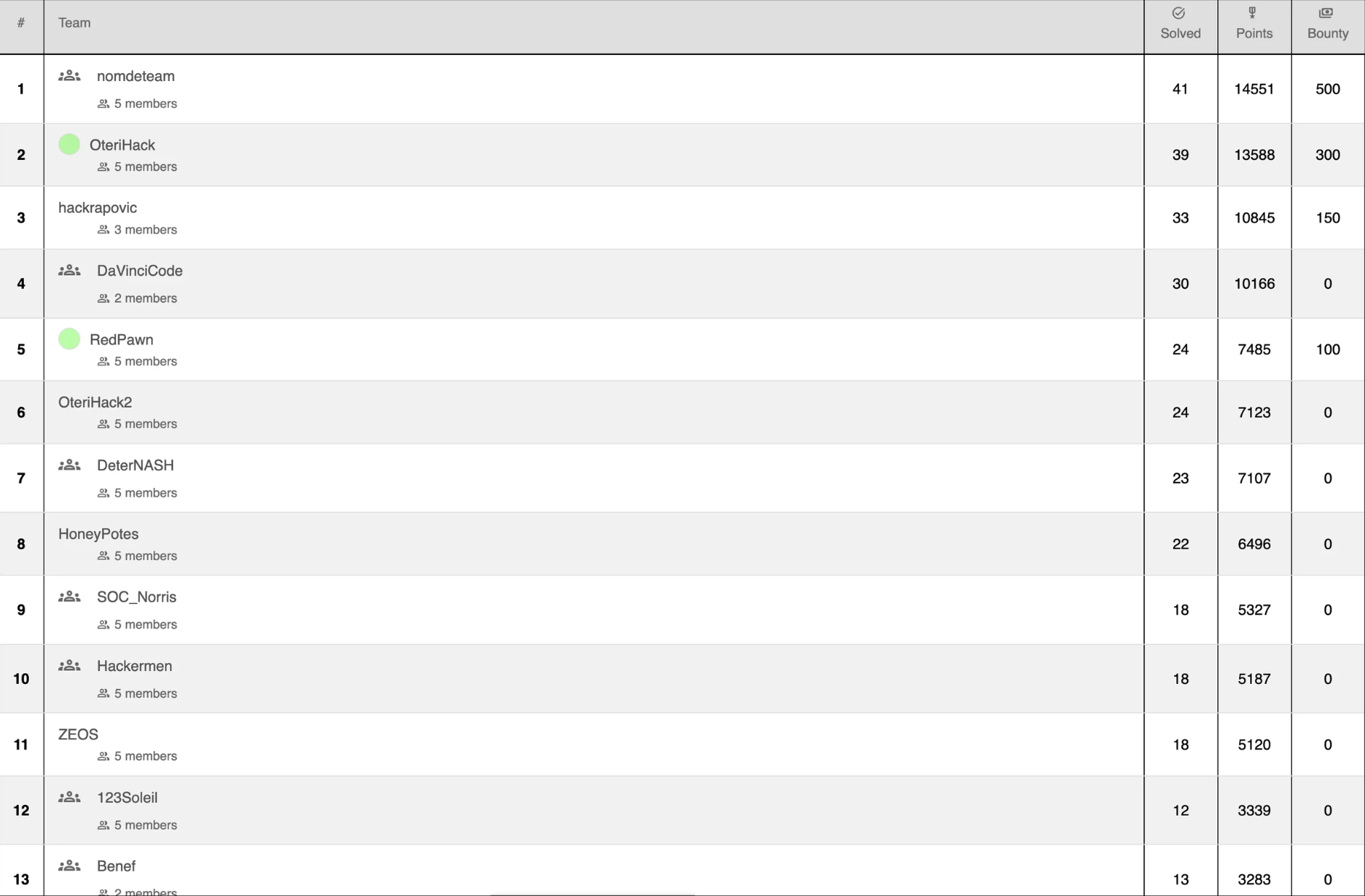
On voit que dès la 5ème place on arrive à peine à 50% de résolution.
Cependant, le nombre de solve par challenge est absolument inutile si on ne peut pas le corréler à une qualité globale. Ici on a eu une note de 4,2 sur 5 sur les deux groupes. Cela veut dire que les joueurs, en plus d'avoir trouver les challenges intéressants, ont pris autant de plaisir à les résoudre AVEC ou SANS IA, ce qui est notre plus grosse victoire 😎.
Fun fact : le groupe AI a eu tendance à trouver les challenges un peu plus guessy et plus faciles que les utilisateurs sans IA 🤡. Malheureusement le nombre de votes ne permet pas une comparaison statistiquement solide, mais c'est la micro-tendance qui se dégage. Faites-en ce que vous voulez.
On voit aussi que la moyenne de tentatives par challenge est 4x plus haute sur les challenges côté AI. Pourtant, lorsqu'une équipe résout effectivement un challenge, il lui faut un nombre de tentatives presque égal pour y arriver, AI ou pas.
Cela veut dire que de manière générale les joueurs qui utilisent l'IA ont tendance à rentrer des flags hallucinés sans vérifier. Nous avions de notre côté défini une limite de tentatives par challenge pour ne pas trop punir cet effet.
Direct feedback
Durant le CTF nous avons fait le tour de tous les participants pour demander individuellement comment ils trouvaient la compétition et si l'IA gâchait le plaisir de flag. Nous avons interrogé 119 personnes exactement.
- 118 sur 119 ont répondu que les challenges étaient intéressants à résoudre même avec AI et que globalement ils étaient surpris d'une telle résistance.
- 1 sur 119 nous a dit qu'en effet ça résiste pas mal, mais qu'au final ça restera qu'une question de token et qu'il suffit juste d'en consommer plus, et que donc ça ne nous rendait pas plus résistant qu'une autre compétition.
À l'image de nos solves qui ne valent rien sans une note sur les challenges, la note ne vaut rien sans des feedbacks directs. Dans l'absolu ils ont tous été ultra positifs, mais une image vaut plus que mille mots, alors je vous laisse le feedback de l'équipe arrivée deuxième et de celle arrivée sixième, qui ont l'habitude des CTF.
