Post-mortem — comment on a rundown un CTF pour 1167 participants
Contexte — l'opportunité
Pour comprendre ce post-mortem, il faut comprendre où on en était avec Harem (notre plateforme CTF maison) avant cet événement.
Depuis 4 éditions on organise Hack'In, un CTF annuel qu'on monte avec une bande de passionnés. Au total sur ces 4 éditions : +500 visiteurs, +350 participants, +25 sponsors, +150 challenges créés. Avant 2024 on utilisait CTFd puis CTFCafé, et on passait plus de temps à ramasser la plateforme par terre qu'à s'occuper de nos participants. Chaque édition on finissait avec la plateforme KO à 2h ou 3h du matin devant 150 personnes.
En 2024 on a décidé d'arrêter de s'emmerder et de coder notre propre plateforme — Harem. On l'a testé sur Hack'In 2025 (4,53/5 de note, 54 challenges, 0 problème technique), on l'a utilisée en cours avec des étudiants, sur youpwn.me, sur des petits events d'entreprise. À chaque fois maximum ~150 utilisateurs simultanés.
Et là, fin 2025, Ynov nous contacte pour organiser un CTF inter-campus. Un seul événement, une seule journée, 1167 étudiants inscrits, répartis sur une douzaine de campus en France — Toulouse, Bordeaux, Aix, Paris, Nantes, Rennes, etc. Le plus gros campus à lui seul c'est 33 équipes de 5, soit 165 participants.
C'est l'opportunité qu'on attendait depuis des années.
- Techniquement : c'est le premier vrai test de charge de Harem. Si la plateforme tient, on prouve qu'on peut faire x10 sur la taille d'événement qu'on gérait jusque-là. C'est la validation qu'on vise un marché au-dessus des petits CTFs d'assos.
- Stratégiquement : c'est notre premier gros event avec un vrai contrat. Si ça se passe bien, ça ouvre la porte à d'autres events similaires — universités, écoles, entreprises. Concrètement, c'est le premier euro sérieux pour Harem, après 2 ans passés à développer la plateforme sur nos propres deniers.
- Symboliquement : pour nous, c'est la première fois que Harem quitte notre écosystème (Hack'In + cours) pour être utilisée par du monde qui ne nous connaît pas. C'est le moment où on arrête de faire tourner Harem dans un cadre amical et où on la met face à des utilisateurs qui n'ont rien à faire de notre histoire.
Autant dire que la pression était énorme. Pour un événement de cette ampleur, il ne suffit pas que « la plupart des choses fonctionnent ». Il faut que tout fonctionne, pour tout le monde, pendant 8h.
Présentation de Harem
Déjà pour l'historique il faut savoir que cette plateforme de CTF est 100% développée par nous, 0 framework tiers, 0 CMS, 100% code maison. Pour le meilleur et pour le pire.
Notre stack technique c'est : un « worker » terraform qui manage les VMs, un backend en Node.js, la base de données en MongoDB, un frontend en React, un reverse proxy interne Traefik et un reverse proxy frontal Nginx, le tout hébergé sur GCP dans deux projets différents. Le premier qui accueille les VMs et l'autre la plateforme et le challenge SuperMeeee.
Toute l'infrastructure est conteneurisée dans un docker-compose, on met ça sur une énorme VM, on fait un docker compose up --build et après tout fonctionne as code et automatiquement. C'est-à-dire :
- Création des utilisateurs/teams/roles/etc.
- Provisionnement des VMs dans GCP, setup des firewalls GCP, management d'IP etc.
- Scraping des challenges sur github
- Pré-build et pré-pull de toutes les images github sur chaque VM
- Préparation des comptes SSH, des clés, du monitoring, des confs bizarres pour les challs bizarres
- Validation des challenges pour NE PAS pousser des challenges qui ne fonctionnent pas (flag mal formé, ressources manquantes, etc.)
- Association des teams aux VMs selon les limites
- …
Bref il y a un .env à donner et après avoir up les containers c'est bon. Plus besoin d'intervention humaine.
À savoir que ce n'était pas la première fois que l'on déployait notre plateforme dans un CTF. Ni la première, ni la deuxième, ni la troisième fois.
On avait d'ailleurs organisé un CTF le 27 novembre pour une centaine de personnes pour tester plein de challenges que l'on allait proposer aux participants.
Un point qui a quand même son importance : nous n'avions JAMAIS eu une seule seconde de downtime avant ce jour-là sur la plateforme.
Donc très naturellement on s'est dit que même si 100 personnes c'est pas 1000, on n'avait qu'à faire x12/x13 sur les ressources et on serait TRÈS LARGE car pour 100/150 on provisionnait toujours 4 fois trop. Mais si vous lisez ça c'est que vous vous doutez de la suite de l'histoire 🤡

NB : Vous pouvez retrouver sur le blog l'article
Welcome in our Haremqui présente la plateforme dans son état actuel et les raisons qui nous poussent à l'utiliser.
3 décembre — Day -1
Le 3 décembre cela fait plusieurs jours que des mails d'inscription sont envoyés aux 1167 personnes attendues sur la plateforme.
À ce moment-là on a déjà résolu tous les challenges de la plateforme plusieurs fois, sur plusieurs VMs, tout fonctionne et on pense être prêts.
Dès 9h du matin certains participants commencent à fuzzer la plateforme avec des outils comme feroxbuster et gobuster.
Et là notre VM qui a 16 vCPU et 128 Go de RAM affiche un 502. Et donc là déjà on se dit que c'est VRAIMENT pas normal que quelqu'un puisse faire tomber une si grosse machine avec juste un scan.
Donc on reproduit de notre côté et on prépare des tests de charge. On tourne entre 800 et 3700 req/s. Et ça crash.
On met alors en place un rate limit (on choisit d'utiliser notre nginx et pas d'ajouter un cloudflare ni le service de google pour plein de raisons) et on ajoute ça dans notre config :
# Zone pour l'API : 600 requêtes/seconde par IP avec file d'attente de 300
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=600r/s;
# Zone pour le frontend : 200 requêtes/seconde par IP avec file d'attente de 100
limit_req_zone $binary_remote_addr zone=general_limit:10m rate=200r/s;
# Map pour détecter les outils de bruteforce/scanner
map $http_user_agent $is_scanner {
default 0;
~*feroxbuster 1;
~*gobuster 1;
~*dirb 1;
~*wfuzz 1;
~*nikto 1;
~*sqlmap 1;
~*nmap 1;
"" 1; # User-Agent vide = suspect
}
location /api {
# Rate limiting avec queue pour les clients normaux
# Sans nodelay = les requêtes sont mises en queue et traitées progressivement
limit_req zone=api_limit burst=300;
limit_req_status 429;
# Pour les scanners détectés, block les requêtes
if ($is_scanner) {
return 403;
}
...
}
location / {
# Rate limiting avec queue pour le frontend
limit_req zone=general_limit burst=100;
limit_req_status 429;
...
}Ça fonctionne, maintenant un étudiant peut bloquer tout son campus mais ne pourra pas faire planter la machine (sauf moyens importants).
Sauf qu'à ce moment-là, on prend aussi le risque d'empêcher les appels légitimes.
On calcule alors le nombre de requêtes qui sont faites lorsqu'on appelle une page de notre front. Globalement il y a le front qui fait plusieurs appels pour se construire (css, image…) mais rien de très lourd, puis par page consultée on a en moyenne 5 appels à notre backend de fait.
On prend le campus avec le plus de teams, Toulouse avec 33 teams, il y a 5 participants par team, on fait 33x5 donc 165 étudiants. On se dit qu'ils feront tous à la MÊME seconde des refreshs (hautement improbable) et on fait 165x5=825. Donc pour gérer ce flux « légitime » on prévoit 900 connexions par campus (rate+burst).

Après ça on fait des tests depuis plusieurs IPs, on monte à 3700 req/sec par IP et dès qu'on se connecte avec une autre IP, aucun bug, tout est super fluide.
On monte aussi les perfs de la machine pour doubler le nombre de CPU et on passe à 32 vCPU et 128 Go de RAM en se disant que pour 1500 personnes ça doit être large car ça reste juste une webapp !
4 décembre — Day 0
Vers 00h03 on déploie toutes les VMs sur notre projet prévu pour et là on découvre que littéralement au même moment Google augmente ÉNORMÉMENT nos quotas sur ce projet de VMs (le projet a son importance). Pour info ça fait 4 mois qu'on pleure auprès de Google pour avoir au moins 15 IP publiques et Google nous bloque à 15 bref. Quand on a découvert ça on vous laisse imaginer la réaction.
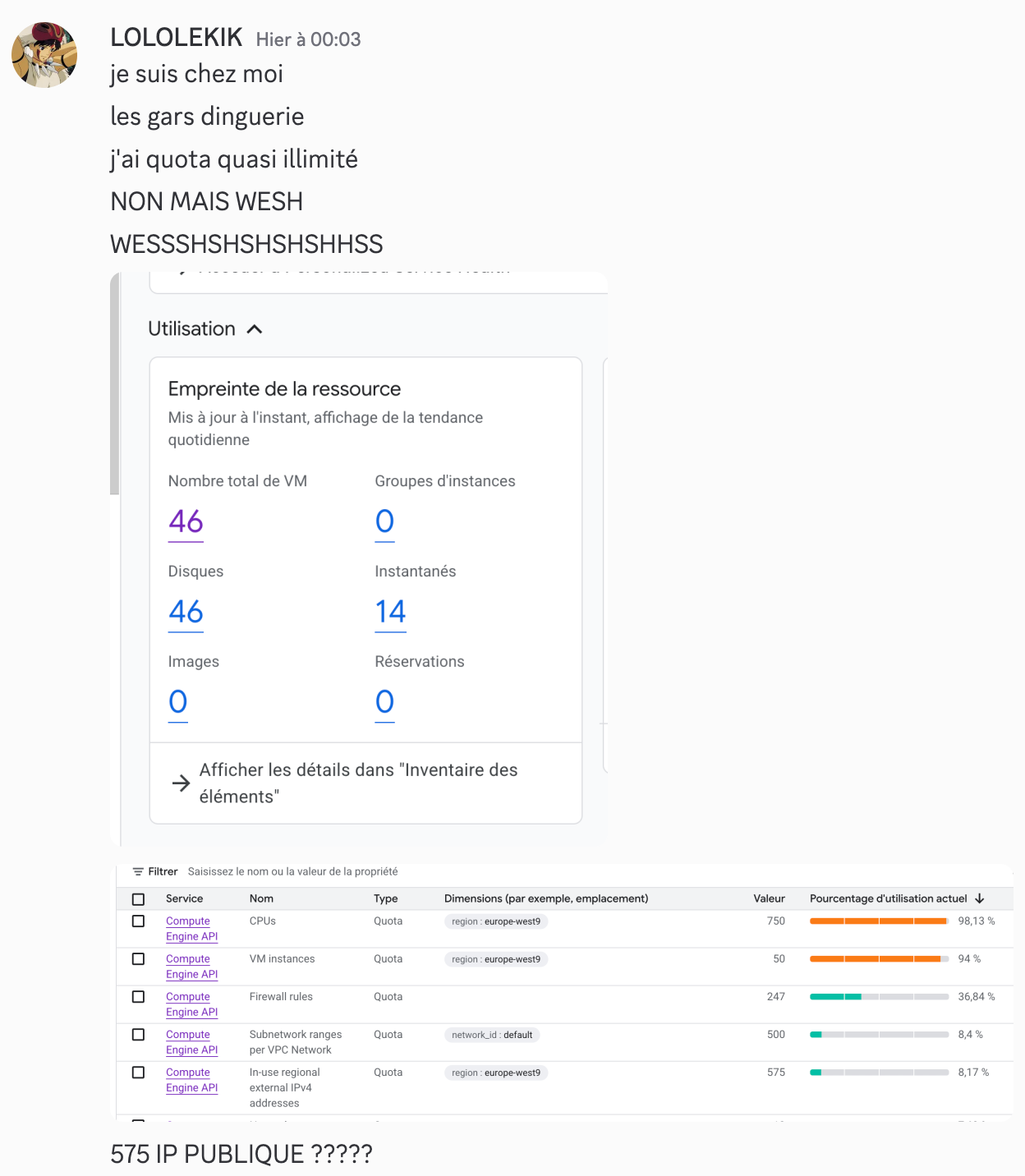
On n'avait pas été prévenus par Google car on a dû pleurer auprès d'un mec du support — bref histoire longue.
On déploie alors 50 VMs de e2-standard-8 (8 vCPU, 32 Go de mémoire), on build tous les challenges dessus et on affecte 4 teams par VM. Et ça nous utilise même pas la moitié de nos quotas.
On vous passe aussi la partie où une RCE est sortie sur notre stack car ça n'a pas son importance dans ce post-mortem, en tout cas toute l'équipe a dormi moins de 3h cette nuit-là.
On arrive à Ynov à 8h30 et voici notre espérance du moment :

Bref 9h15 et là 0 challenges, le front fonctionne mais 0 challenge.
On voit qu'on a 0 réponse du backend. Ça peut pas être la gestion de nos containers car les participants n'avaient même pas accès au challenge. Le backend ne tient juste pas la charge. C'est notre première conclusion.
On regarde notre htop sur la machine et là on voit qu'on a 1 Go de RAM utilisé et, ok, nos CPU consomment un peu mais ils ne sont pas full. Donc niveau perf on semble bien.
On se dit que c'est un problème qu'on va régler en 5-10 minutes. Si les performances sont bonnes, alors c'est le rate limiting côté backend qui ne suit pas.
On change la config du nginx pour quelque chose de plus permissif :
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=900r/s;
limit_req_zone $binary_remote_addr zone=general_limit:10m rate=400r/s;
location /api {
limit_req zone=api_limit burst=600;
limit_req_status 429;
...
}
location / {
limit_req zone=general_limit burst=300;
limit_req_status 429;
...
}Toujours KO, alors on se dit qu'il y a un goulot d'étranglement donc on teste plein de trucs, on limit le rate, on augmente le burst puis l'inverse puis on enlève les limitations.
Et là toujours rien. Jusqu'à 9h30 on fait les mêmes modifs en boucles pour les mêmes résultats (la définition de la folie selon Einstein).
Et c'est quasi instantanément la page blanche. On a littéralement 0 indicateur au rouge.
1er takeaway : superviser un MAXIMUM d'indicateurs.
Et là jusqu'à 9h35 c'est le vide total, c'est littéralement IMPOSSIBLE de savoir, surtout dans l'urgence. On avait des idées pour régler le problème ou investiguer. Sauf que dans nos têtes il fallait que ce soit réglé dans les 5 minutes absolument (voire il y a 5 minutes). Et c'est après ces 2/3 minutes de vide total qu'on s'est dit qu'il fallait bien faire quelque chose et qu'on allait remonter une instance. Même si de notre point de vue c'était pas un problème de perf (pour ça qu'on ne l'avait pas fait dès le début) il fallait au moins essayer des trucs.
2ème takeaway : ne pas hésiter à lancer un mode de résolution « long » dès le début, au cas où on ne règle pas tout en 5 minutes.
Dernière chose : on aurait pu avoir la possibilité d'augmenter les ressources de notre plateforme, sauf que la plateforme ne se trouve pas dans la zone avec les quotas augmentés. Et sur cette zone-là on était déjà à 100% de CPU. Et là on se souvient que Google nous a mis des quotas quasi illimités sur notre autre projet. Sauf qu'on ne peut pas migrer facilement une VM d'un projet à l'autre, et ça on l'avait testé il y a moins d'une semaine.
Donc on change de projet, on prend la VM qui nous paraît la plus overkill.

On prend une n2-highmem-64 (64 vCPU, 512 Go de mémoire) et là impossible de la créer. On avait atteint notre nombre max de VMs sur le projet (on était toujours à 50). Donc on supprime une VM au pif en se disant que ça n'impacterait que 4 équipes mais que ça pourrait sauver tout le monde. Donc on envoie de la force aux teams suivantes qui ont dû attendre encore PLUS que les autres pour pouvoir commencer :
- BOR7
- AIX16
- PAR21
- NAN4
Et là c'est parti à 9:35:52 on commence à refaire de ZÉRO tout ce qu'on avait préparé. Dont faire des trucs qu'on n'avait pas prévu comme exporter toute la bdd pour la rebasculer sur l'autre instance, car on ne pouvait pas juste repopuler les utilisateurs sinon tout le monde aurait perdu son mot de passe etc.
3ème takeaway : préparer les scripts d'urgence de backup et prier pour ne jamais en avoir besoin.
Car ce n'était pas juste monter une nouvelle plateforme, il fallait que tout soit ISO à l'ancienne pour continuer d'utiliser toutes les VMs provisionnées avec les bonnes clés SSH, tokens github etc.
Donc :
- 9:35:52 — Création de la VM
- 9:38:54 — Récupération de tout le code de notre plateforme sur notre github
- 9:41:30 — Installation des prérequis comme docker
- 9:42:24 — Validation des nouveaux certificats pour ynov2
- 9:59:56 — Récupération et repopulation de toute l'ancienne BDD
- 10:03:37 — Code 200 sur la plateforme et confirmation que ça fonctionne
- 10:04:?? — Début de la communication sur discord de ynov2.hackin.fr
- 10:05:21 — Validation du premier flag par victor-w-REN
- 10:05:?? — Plateform down
On venait de passer 30 minutes pour tout redéployer ISO et en moins d'UNE minute on se retrouve dans l'exact même situation qu'avant.
On reprend alors notre archi et voici les conclusions qu'on peut tirer sur les services :
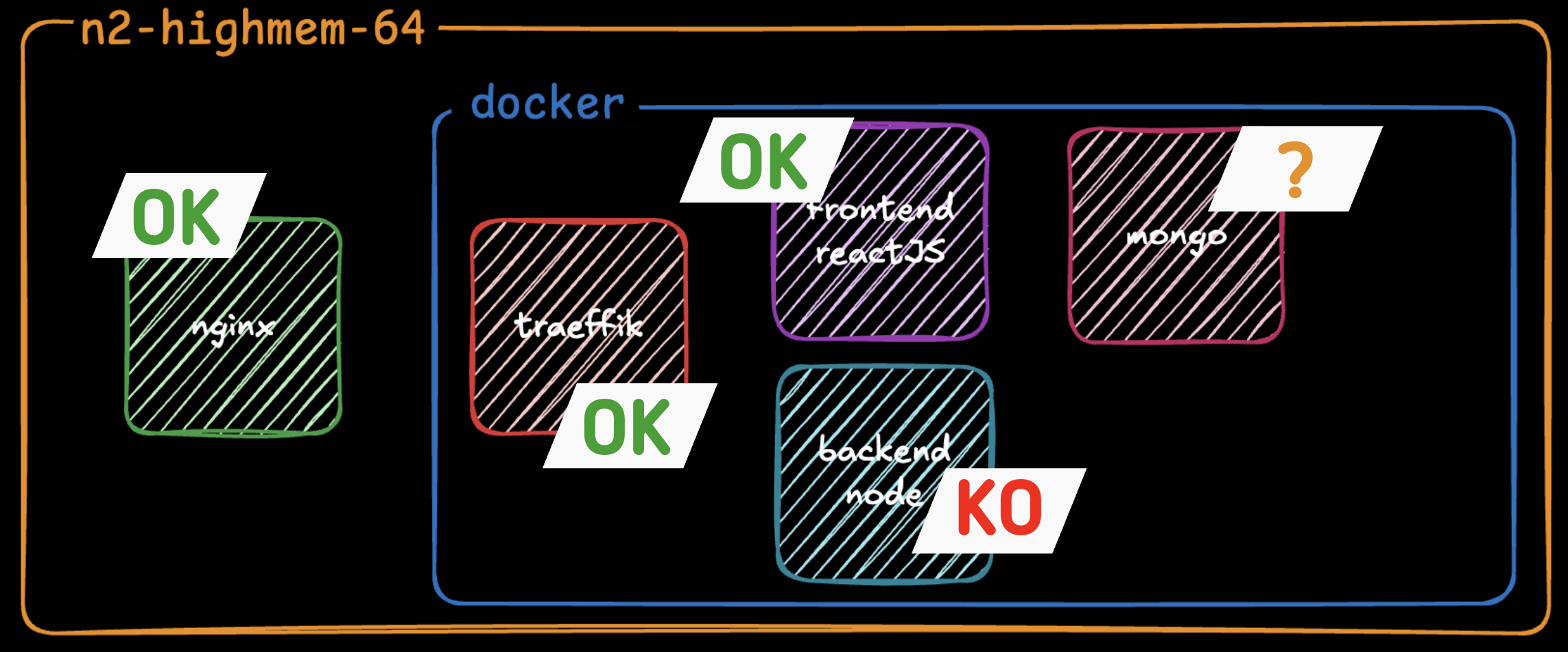
On ne sait pas dans quel état est notre BDD mais en tout cas on est SÛRS que notre backend ne répond pas.
On regarde encore notre htop, et l'évidence est toujours la même. Nos containers n'utilisent PAS les ressources de notre VM.
Mais cette fois ça apparaît plus clairement. On a un CPU qui est à 100% d'usage et tous les autres à peine utilisés.
Pourtant dans notre docker-compose.yml on ne spécifie aucune limite sur l'utilisation des ressources. On prend donc la direction de mettre des limites mais énormes pour voir si ça débloque les containers et de forcer l'utilisation des CPUs.
Voici les commits faits :
- 10:13:13 — KO
- 10:15:06 — KO
- 10:16:09 — KO
- 10:30:53 — KO
- 10:36:07 — KO
- 10:38:31 — KO
- 10:39:57 — KO
- 10:42:29 — KO
- 10:43:30 — KO
- 10:43:52 — KO
- 10:45:26 — KO
- 10:46:59 — OK
On a testé en tout une dizaine de configurations pour que ça fonctionne. Voici ce qui a vraiment tout changé.
Les solutions mises en place
Déjà il faut savoir que Node.js est monothreadé. Donc on a commencé par faire une implémentation de cluster node qui allait nous permettre de créer plusieurs processus qui allaient tourner sur un CPU différent. On allait enfin permettre à notre application d'utiliser les ressources qu'on lui donnait. Pour ça voici l'implémentation qui a été faite :
const cluster = require('cluster');
const os = require('os');
// Utiliser la variable d'environnement ou le nombre de CPUs disponibles
const numCPUs = parseInt(process.env.NODE_CLUSTER_WORKERS) || Math.min(16, os.cpus().length);
if (cluster.isPrimary) {
console.log(`Primary process ${process.pid} is running`);
console.log(`Starting ${numCPUs} workers...`);
// Fork workers
for (let i = 0; i < numCPUs; i++) {
const worker = cluster.fork();
console.log(`Forked worker ${worker.process.pid}`);
}
cluster.on('exit', (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died (code: ${code}, signal: ${signal}). Restarting...`);
const newWorker = cluster.fork();
console.log(`New worker ${newWorker.process.pid} started`);
});
// Log worker events
cluster.on('online', (worker) => {
console.log(`Worker ${worker.process.pid} is online`);
});
cluster.on('listening', (worker, address) => {
console.log(`Worker ${worker.process.pid} is listening on ${address.address}:${address.port}`);
});
} else {
// Worker process - start the app
require('./app.js');
}Puis on démarre notre application avec :
node ./src/cluster.jsEnsuite on a ajouté des options de connexion à notre base mongo :
const connectDB = async () => {
try {
const options = {
maxPoolSize: 100, // Maximum number of connections in the pool
minPoolSize: 10, // Minimum number of connections in the pool
maxIdleTimeMS: 30000, // Close connections after 30 seconds of inactivity
serverSelectionTimeoutMS: 5000, // How long to try selecting a server
socketTimeoutMS: 45000, // How long to wait for a socket to be available
bufferMaxEntries: 0, // Disable mongoose buffering
bufferCommands: false, // Disable mongoose buffering
};
await mongoose.connect(mongoURI, options);
console.log('MongoDB connected');
}
...
}Malheureusement on pense que ces options auraient pu être grandement améliorées. Elles ont sûrement été trop restrictives mais à chaque fois qu'on les modifiait (dont le maxPoolSize) on avait l'impression que la plateforme ralentissait encore énormément. Donc on a laissé comme ceci mais il y a clairement de la marge de progression.
On a aussi tenté d'améliorer notre traefik pour lui faire accepter des délais de réponse du backend un peu plus longs sans drop les connexions, et on a aussi rajouté une limite de requêtes concurrentes. Car si le backend met du temps à répondre on ne voulait pas continuer de le surcharger. Voici les options rajoutées :
traefikhackin:
image: traefik:latest
container_name: traefikhackin
command:
- "--api.insecure=true"
- "--providers.file.directory=/etc/traefik/dynamic"
- "--providers.file.watch=true"
- "--entrypoints.web.address=:80"
- "--entrypoints.web.transport.respondingTimeouts.readTimeout=300s"
- "--entrypoints.web.transport.respondingTimeouts.writeTimeout=300s"
- "--entrypoints.web.transport.respondingTimeouts.idleTimeout=360s"
- "--entrypoints.web.http2.maxConcurrentStreams=1000"
- "--log.level=INFO"
- "--accesslog=true"
- "--accesslog.bufferingSize=100"Et enfin on a réservé de l'espace exprès pour nos services dans le docker-compose :
backendhackin:
build:
context: ./backend
dockerfile: Dockerfile-prod
container_name: backendhackin
deploy:
resources:
limits:
cpus: '48.0'
memory: 96G
reservations:
cpus: '16.0'
memory: 32G
...
mongohackin:
image: mongo:latest
container_name: mongohackin
deploy:
resources:
limits:
cpus: '32.0'
memory: 400G
reservations:
cpus: '16.0'
memory: 200Gmongod
--wiredTigerCacheSizeGB=300
--wiredTigerCollectionBlockCompressor=snappy
--wiredTigerIndexPrefixCompression=true
--logRotate=reopen
--logappendAvec toutes ces modifications les participants ont pu commencer à accéder à la plateforme et lancer des challenges à partir de 10:46:59. Donc avec 1h30 de retard.
4ème takeaway : pour les productions, il vaut mieux indiquer CLAIREMENT les ressources que l'on veut que notre application utilise, plutôt que la laisser consommer « ce qu'elle a besoin ».
Suite de la journée

Suite à ça on pensait qu'on en avait fini, sauf qu'au moment de la pause (on ne sait pas pourquoi à ce moment-là) la plateforme a recommencé à se down. On a donc poussé deux modifications à 13:16:47 et 13:20:09 en jouant sur les paramètres plus haut pour essayer de trouver un équilibre.
À partir de 13h30 le leaderboard ne s'affichait plus pour personne. Et les challenges étaient de plus en plus complexes à obtenir. On a supposé que c'était parce que la base de données était mal configurée et n'arrivait pas à gérer le nombre important de data. En effet dans notre base de données on n'a pas une table leaderboard qui est mise à jour à chaque solve. Mais on a des users qui ont des listes de challenges accomplis qui eux-mêmes valent des points, mais qui sont dégressifs en fonction d'autres solves etc. Par conséquent il y a beaucoup de requêtes à faire en base pour gérer toutes les informations. Et il suffit qu'une seule plante (car plus de pool disponible ou autre) et impossible d'obtenir des informations. Donc on a développé en custom un système de retry pour rejouer les requêtes qui avaient échoué. Voici le bout de code en question :
async function retryMongoOperation(operation, maxRetries = 3, delay = 1000) {
let lastError;
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
return await operation();
} catch (error) {
lastError = error;
const isMongoConnectionError =
error.name === 'MongoPoolClearedError' ||
error.name === 'MongoNetworkError' ||
error.code === 'EPIPE' ||
error.message?.includes('connection') ||
error.message?.includes('socket') ||
error.message?.includes('closed');
if (isMongoConnectionError && attempt < maxRetries) {
const waitTime = delay * attempt; // Backoff exponentiel
console.log(`MongoDB connection error (attempt ${attempt}/${maxRetries}), retrying in ${waitTime}ms...`);
await new Promise(resolve => setTimeout(resolve, waitTime));
continue;
}
throw error;
}
}
throw lastError;
}
module.exports = { retryMongoOperation };On a eu beaucoup de mal à faire fonctionner cette feature et on a dû faire plusieurs push, mais une fois que ça a été fait on a pu survivre le reste de la journée.
On a redéployé le code à :
- 12:53:01
- 13:00:19
- 13:03:45
En tout on a testé et rebuild notre code en production 17 fois et redéployé 25 fois la plateforme sur ynov2.hackin.fr.
Le pire là-dedans ? C'est que notre plus gros pic de RAM a été à 5,89% de sa capacité maximale à 13:22:00 et notre pic d'usage de CPU a été à 42,34% à 17:02:00.
On a aussi eu 363 tickets ouverts et 874,75 € de conso GCP en 12h.
Conclusion
En conclusion ce qui nous a causé du tort, c'était ni la sécurité, ni la bande passante, ni la sous-estimation de la charge qu'on allait recevoir. Mais plutôt la mauvaise gestion des ressources par notre codebase.
Au final il ne suffit pas de prendre juste une grosse machine pour faire tourner une application, ce qui compte c'est que la codebase sache utiliser ses ressources !
Côté opportunité, et c'est la partie qu'on ne peut pas mettre sur un graph : on a quand même tenu. La compétition a eu lieu, les participants ont pu jouer, rire, flag, râler, gagner. Et l'édition suivante (Hack'In 2026) a atteint 4,90/5 de satisfaction plateforme — avec ces apprentissages intégrés. Un échec partiel à 1h30, mais un gain de maturité qu'on n'aurait jamais obtenu à 150 personnes.
J'espère que cet article vous aura appris des trucs. En tout cas nous beaucoup, et on connaît désormais la direction à prendre pour améliorer notre plateforme.