Research: AI vs. CTFs
⚠️ Disclaimer
Everything described in this article worked at the 5th edition of Hack'In, on April 11, 2026. On that day, with this lineup of models (Claude Sonnet 4.6 / Opus 4.6 — with and without extended thinking, GPT-5, Gemini 2.5 Thinking, etc.), with these agentic capabilities, with this context window size, we managed to deliver a CTF that remained interesting and difficult even for teams spamming AI.
However: what works today probably won't work in 6 months. Models are progressing fast, agents are getting better at handling long context, at running tools, at iterating. Most of the techniques described here exploit current limitations of LLMs: context pollution that makes them diverge, the lack of training data on out-of-distribution challenges, attention biases on first/last instructions at the expense of the middle, etc.
All of this is a snapshot at one moment in time. The goal of this article isn't to provide the ultimate AI-proof CTF recipe. It's to share an approach, some heuristics, and above all the mindset we adopted: we're not trying to block AI, we're trying to keep the challenge interesting even with it.
If you're reading this in 2027 and the techniques no longer work, that's normal. Adapt.
NB: This article focuses on the technical "anti-AI" angle. The full retrospective on the edition (organization, community, what we learned as a team) will come in a separate article, after the Hack'In 5th edition event.
State of play late 2025 / early 2026
Before diving into the topic, a quick sourced overview. Without this context, this article looks like a whim. For 18 months, the CTF world has been going through an existential crisis because of LLMs, and what we did at Hack'In fits into that — we didn't start from nothing, we started from the conviction that the community had been asking the wrong question.
To give a quantitative measure of the crisis: Jacob Krell (Suzu Labs) analyzed the first blood times of 423 Hack The Box machines released between March 2017 and October 2025. Conclusion: root blood times are declining by about 16% per year in log-space, with marked acceleration after the arrival of LLMs and agentic exploitation frameworks (Security Boulevard, March 2026). Concretely, by extrapolating the curve: what took a top hacker 8 hours in 2020 is done in roughly 3 hours today, with a marked elbow post-2023.
The BSidesSF 2026 drama — the event that blew up the debate
Legendary edition, well-known organizers, technical audience. Result of the April 2026 competition, as documented by Include Security in their post "CTFs in the AI Era":
- 16 teams solved EVERY challenge
- No challenge had fewer than 25 solves
- The top 10 teams were fully automated — Claude Code and Codex agents
- Most challs were flagged a few minutes after release
- Apart from 2-3 OSINT challenges, Claude/Codex could solve every challenge, including crypto and binary exploitation that would have been "unsolved" the year before
For reference: in 2025, on the same CTF, the winning team was the only one to come close to a full solve (Include Security, idem). One year later, full solve + 15 other teams behind. The difference? The arrival of agents.
The Veria Labs team even open-sourced the agent they used (github.com/verialabs/ctf-agent), with the repo titled: "Autonomous CTF solver that races multiple AI models in parallel. 1st place BSidesSF 2026". It has become a commodity.
Other events that made noise
hxp — December 2025. One of the most respected CTFs in the world. The cryptography category was described as "autonomously sloppable" — AI alone could spit out the solutions (Include Security, April 2026).
DEF CON CTF Finals 2025 — August. At least 2 finals challenges were solved with major LLM assistance. Wil Gibbs documented on his blog one of these solves as "the first time I see a challenge at this level being bypassed via MCP".
picoCTF 2025. Academic evaluations (notably via SWE-Agent — the framework from Princeton/CMU originally designed to have an LLM agent solve software engineering tasks, repurposed for security evals — and other baselines) showed that with 3 attempts per challenge, a solo agent autonomously solves ~15 challs — especially easy/medium ones in reverse, crypto, web and forensic. picoCTF itself published a post on AI in cybersecurity in September 2025 acknowledging the shift. The most well-known learning CTF in the world has become an LLM benchmark.
HTB AI vs Human Challenge — April 2025. Competition explicitly pitting 8 agent teams against 403 human teams, on 20 crypto/reverse challs, 48h, $7,500 cash prize. 5 of the 8 AI teams individually solved 19/20 challs (Hack The Box, May 2025). Humans only retained the advantage on the final multi-stage challenge.
HTB / NeuroGrid CTF Benchmark — March 2026. 1,078 teams (120 AI-augmented, 958 human-only), 36 challs across 9 domains, 3 days. Results published by HTB (benchmark report, March 2026):
- Solve rate: 27% for AI-augmented vs 16% for human-only (top teams)
- 3-4x productivity gain for "elite augmented" teams
- AI advantage peaks at medium difficulty (3.89x), drops back to 2.97x on hard
- Over 70% improvement in solve rate at equal time window
Organizers' and community frustration
Beyond the numbers, there's a massive frustration running through the community, and it's increasingly public. Three different angles worth reading in full:
The structural assessment — Krell (Suzu Labs / Security Boulevard). For Jacob Krell ("The Death of the CTF: How Agentic AI Is Reshaping Competitive Hacking", March 2026), agents have structural advantages that humans won't catch up on: error-free output parsing, access to the entire public corpus of vuln research, multi-source synthesis without cognitive fatigue, no working memory limits. His conclusion targets recruiters: an HTB top-100 in 2026 might reflect manual exploit skills… or it might reflect that the candidate just has a good agentic pipeline. The leaderboard has lost its meaning as a proxy.
The loss of the soul of CTF — k3ng. The post "CTF is dead*" captures the "emotional" angle better than anyone else. For k3ng, the problem isn't the number of CTFs (there are still more and more), it's what happens at them. Leaderboards are full of full-solves, but there's no more discussion after the competition: writeups have become "collections of AI-style solve scripts", and when AI "slops through" all the challs, there's nothing left to talk about. Historic CTF rested on curiosity, unintended solutions, sharing experience — all of that has gone silent.
Players' grievance — r/securityCTF. The Reddit thread "CTFs are dead and we killed them" is the participant-side mirror of k3ng's post. The title says it all: the community points the finger at the fact that it's the players themselves who normalized agentic usage to the point where the format no longer holds.
Individual public stances. On X too, organizers and players have publicly slammed the door or expressed weariness. See in particular @_mixy1 and @Fried_rice — statements that circulate widely in the scene and reflect a shared frustration.
On the concrete reactions from organizers since late 2025 (see Include Security for the round-up):
- Some ban AI in the rules (unverifiable, but a statement of principle)
- Others have created separate categories "AI-allowed / AI-forbidden"
- Others have switched to invite-only or on-site only to limit agentic scaling
- And many small organizers have simply stopped, tired of seeing 6 months of prep wiped out in 30 minutes
The general feeling, in early 2026, is that nobody has really managed to run a public CTF that stays interesting in open-AI on the long format. Either you ban (and turn a blind eye), or you watch your competition get automated.
Why this article
That's where we come in. Hack'In 5th edition was our attempt to prove there's a third way: take AI as an environmental variable, and design against it. Don't ban, don't separate, don't give up. Just design better.
On April 11, 2026, with 130 participants in full open-AI, we held out for 12 hours without the competition collapsing. Only 5 teams solved more than half the challs, and the satisfaction feedback came in at 4.2/5 on both the AI side and the no-AI side. It's not BSidesSF 2026 (not the same scale), but on the open-AI format, it's the closest thing to a proof that you can still design for humans in 2026.
It's not a magic recipe (cf. disclaimer). It's a retrospective. The rest of the article details how.
To dig deeper
If you want the full context before reading on:
- Krell, Jacob. "The Death of the CTF: How Agentic AI Is Reshaping Competitive Hacking". Security Boulevard / Suzu Labs, March 2026. — the most solid quantitative analysis right now.
- Include Security Research Blog. "CTFs in the AI Era". April 2026. — the BSidesSF 2026 retrospective.
- k3ng. "CTF is dead*". — the loss of the community fabric behind the leaderboards.
- r/securityCTF. "CTFs are dead and we killed them". — the players' side.
- Gibbs, Wil. "All You Need Is MCP — LLMs Solving a DEF CON CTF Finals Challenge". — one of the first major MCP-assisted solves at a top-tier CTF.
- Hack The Box. "AI vs Human: CTF results show AI agents can rival top hackers" (May 2025) and "HTB Benchmark Report" (March 2026). — the two quantitative benchmarks.
- picoCTF. "What I Wish More People Knew About AI in Cybersecurity". September 2025.
- @_mixy1 on X, @Fried_rice on X. — two individual public stances in the community.
- Veria Labs.
ctf-agent. — the open-source repo of the BSidesSF 2026 winner.
Context — why ask the question
For the 5th edition of Hack'In, we wanted to raise the bar another notch. For the 4 previous editions we were on "beginner friendly", with lots of easy challs to make people want to keep going. Since last year we've been trying to deliver a more "exclusive" competition.
The final format:
- 48 challenges
- 15 categories
- 12 hours of CTF (i.e. ~3 Claude sessions for those who pay the max plan)
- 0 restriction on AI usage
- 1 promise: that the competition stays interesting, even with AI
Restricting AI usage in competition is a really, really hot topic in the community since 2025. We could have banned AI in the rules. Except:
- It's unverifiable (we're not going to look over the shoulders of 50 teams)
- It's anachronistic: in 2026 nobody does cyber without AI anymore, no more than anyone coded without Stack Overflow in 2010
- It's lazy: it punts the design problem to the rules
So we go the other way: we assume all teams use Claude/GPT/Gemini in agentic mode, and we design challs starting from there.
Our position
Before diving into the technical side, we need to set the frame:
The goal is NOT to prevent AI from solving the challenges. The goal is to design challenges that stay interesting WITH AND without AI.
It's an important nuance. A chall that takes a human 30 seconds and AI 5 seconds is bad. A chall no AI can solve but no human can either is also bad. The sweet spot is:
- A solo human can solve it if they understand the topic
- A solo AI struggles without human guidance
- Human + AI is faster than human alone, but not infinitely so
AI must remain a tool, not a replacement. If solving boils down to "copy the brief into Claude and paste back the answer", we've lost.
Understanding "AI"
Before touching a single chall, we spent time understanding how LLMs work and especially how they're used in a CTF context. This section is deliberately popularized — the idea is that even if you've never opened a paper on transformers, you understand why the techniques that follow work.
A brief aside: how an LLM works (TL;DR)
Three things to internalize for what follows:
1. Everything is a token. When you send a prompt to Claude, the text is first cut into "tokens" (basically chunks of words). The model doesn't see text, it sees a sequence of numerical IDs. A session with 100k tokens loaded is the equivalent of ~75,000 words of context.
2. The model predicts the next token. At each step, the LLM looks at all the context (system prompt + conversation + its own ongoing generation) and computes the probability distribution of the next token. It has no "separate thought" from the token stream, everything goes through this autoregressive prediction loop.
3. Attention is expensive and gets diluted. The central mechanism of transformers is self-attention: each token looks at all the others to decide what's important. The memory/compute cost is O(n²) on context size — in theory. In practice, 2026 implementations (FlashAttention-3, sliding window, ring attention, sparse attention) significantly mitigate this cost. But the attention dilution phenomenon remains: the longer the context, the less attention available "per useful token". It's not just "the model has more to read" — it's that it becomes statistically less able to weigh correctly what matters.
This last point is the real lever. When we talk about "context pollution", we're talking about this attention dilution.
Three LLM cognitive biases you need to know
These three biases are academically documented and they're precisely what we exploited in the chall design.
Primacy effect. LLMs grant disproportionate attention to the first tokens of context. Empirically, that's generally where the system prompt, the general instructions, and the user's directive live. Modifying the start of a prompt has much more behavioral impact than modifying the middle — that's also why "prefix-based" jailbreaks work well.
Recency bias. Symmetrically, the most recent tokens have a strong influence on prediction. That's what lets Claude answer your last question rather than the one from 10 messages ago. In an agent, it's also the reason a weird last tool output can totally derail the resolution plan.
Lost in the Middle. The trough between the two. Liu et al. (2023, "Lost in the Middle: How Language Models Use Long Contexts", arxiv:2307.03172) demonstrated a U-shaped curve on retrieval tasks: a model retrieves an info placed at the start or end of context very well, but its performance drops drastically when the info is placed in the middle. The original paper tested up to 16k of context; the phenomenon has since been reproduced on longer windows, with variants depending on architectures.
Important for 2026: frontier models (Claude 4.6, GPT-5, Gemini 2.5) have been specifically trained against this bias via "needle-in-a-haystack" benchmarks, long-context fine-tuning, and hybrid architectures. The phenomenon persists, but has significantly diminished. That's precisely one of the reasons this technique will have a limited shelf life — each next generation handles long contexts better.
Concretely for us: if an info is placed at the start (the chall description) or has just arrived (the last tool output), AI takes it into account. If it's drowned in the middle of a long conversation with 30 tool iterations and 50k tokens of logs, it can literally disappear from the model's "active memory".
That's what makes all our techniques exploitable.
The knowledge cutoff
Crucial detail we'll exploit extensively: an LLM is trained on a corpus frozen at a given point in time. This knowledge cutoff is generally between 6 and 18 months before the model's deployment (Claude Opus 4.6 has a cutoff of May and August 2025, for example, and Opus 4.7 in January 2026).
Anything published after the cutoff — CVEs, writeups, papers, OSS code — isn't in the model's weights. AI may possibly retrieve it via web search or in the context we provide, but it has no statistical intuition on it. On pre-cutoff topics, a model is unbeatable. On post-cutoff topics, it's just decent like a human reading the topic for the first time would have been — or even worse, because it has less experience to fill in the gaps and tends to forcibly pattern-match on what it knows.
It's the sole structural foundation of our Technique #1 (the 0-days).
Note on reasoning models (extended thinking)
2026 models all have an extra capability we explicitly factored into our study: extended thinking mode (or reasoning mode). Claude 4.6 with a thinking budget, GPT-5, Gemini 2.5 Thinking can deliberate internally before answering — they silently generate hundreds to thousands of reasoning tokens before output, which lets them plan, self-critique, and revisit their choices.
In theory, these models should be much more resistant to our techniques:
- They better detect dead-ends (Technique #2)
- They're less likely to "confirm" a bad finding without verifying (Technique #3)
- They plan long exploits instead of running them by reflex (Technique #4)
- They better contextualize misleading descriptions (Technique #5)
In practice, they did perform better than non-thinking modes. But not enough to invalidate our techniques:
- Thinking budget remains finite, and it consumes a huge amount of output tokens — which further accelerates user plan exhaustion
- Internal reasoning is itself subject to lost in the middle and to the primacy effect, because it's generated in the same window
- It doesn't correct for the primacy effect when the user copy-pastes the misleading description directly without letting the model question it
- On "relationship to time" traps (Technique #4), thinking changes nothing: the human is still impatient
That said, this is exactly the kind of capability that will make this article obsolete. Reasoning modes are advancing fast, the trend shows a continuous reduction of the biases we exploit.
On the AI side, what counts in competition
| Lever | Explanation |
|---|---|
| The prompt | The more precise it is, the faster AI goes. If the brief is ambiguous or noisy, AI scatters in all directions (cf. primacy effect: the initial description weighs heavily) |
| The context window | Sonnet 4.6 / Opus 4.6: 200k tokens standard, up to 1M on dedicated endpoints. Once saturated, the model forgets or diverges — and well before saturation, "lost in the middle" already degrades quality |
| Token-by-token generation | AI predicts the next token based on context. The more similar patterns it has seen in training, the more efficient it is |
| The token cost of an exploration | Each tool call, each bulky output weighs. A large codebase to analyze drains the budget |
| Agentic capabilities | Claude Code / Cursor can run code, scan, iterate. But they remain limited by context and session duration |
| Ethics and guardrails | Models can refuse certain actions (explicit RCE, exfiltration, etc.) |
On the human side, what also counts
The human piloting the AI has their own weaknesses we can exploit:
- Waiting: a human waiting 3 minutes in front of a prompt will lose patience
- Frustration: 4 failed attempts and the user resets the session, loses all the context
- Workflow: most people do "copy the brief → ask Claude → try the answer". That's exploitable
- Difficulty distribution: the more easy challenges you have, the more AI-friendly the competition will be
Keep in mind that what's going to differentiate a human from a machine is their relationship to time and their emotions.
Our objective
Our objective is to find the right recipe to reward players who use AI by understanding the challenges and to punish those who throw random agents at things without understanding. So we're going to play on three key resources:
- Context: the bigger the context, the more attention dilutes, the less relevant the model becomes → we want to fill it.
- Tokens: it's the holy grail. Once there are no more tokens (session limit, paid plan exhausted, saturated window), we force the user to roll up their sleeves → we need to consume as many as possible.
- Patience: nobody likes waiting in front of a prompt → we want to force the user to wonder "why is the model struggling" and force them to understand the challenge to unblock it.
By consuming context, tokens and human patience, we force the participant to say "ok, let me look at what's going on".
And for that we'll use:
- The workflows of people who throw AI at everything
- The way LLMs themselves work (the three biases above)
- The (hopefully) limited money of participants — an API plan or a premium session isn't unlimited
Technique #1 — "The most technical CTF"
The idea
No easy challenges. Only "insane" challs in the strict sense. If we can't make a hard chall on a topic, we drop it as a physical or social engineering one.
Concretely, of the 48 challs proposed:
- 0 challenges classified "easy"
- A significant share based on 0-days we found internally over the previous 6 months
- Several challs based on home-grown research (cf. some articles on this blog)
- "Classic" topics (XSS, SQLi, LFI...) replaced with poorly documented variants
Why it works against AI
An LLM is trained on the past. All CVEs, all public HackTheBox boxes, all CTF writeups, all public OSS code — it has seen it up to its knowledge cutoff (generally 6 to 18 months before deployment), often multiple times. On these topics, it has a massive advantage: it'll spit out the exploit instantly, often before a human has even finished reading the brief.
But on an unpublished 0-day (so post-cutoff by definition), AI has no exploitable statistical intuition. It will have to:
- Load the entire codebase (= burn context)
- Understand the architecture (= burn context)
- Identify potential sinks via abstract reasoning (= burn context AND possible hallucinations)
- Try exploits that don't work → fix → retry (= burn context AND human patience loss)
- At each error the tool output goes back into the context and eats more budget
Concrete example: the camera 0-day
One of our challs relied on a 0-day @spikiky had found on an IP camera firmware.
The whole reverse part burned a lot of tokens (which therefore can no longer be used on other challenges). Then exploitation was done physically via a wifi access point with no internet: nobody was using AI in agentic mode at that point. Finally, it wasn't enough to just "pwn" the camera (a known flow in CTF): you had to manage to understand the proprietary workings of the firmware to be able to take a complete picture rather than a partial one. In a CTF context, this isn't a problem we usually see. So getting a model to "spit out" the right solution would require consuming a lot of tokens, especially since the firmware is proprietary and therefore has limited training on it.
Note also that this is consistent with the HTB benchmark of March 2026: the relative AI advantage peaks on medium difficulty (3.89x) and falls back to 2.97x on hard. Designing only hard/insane challs is also catching AI exactly where its relative advantage is weakest.
Takeaway #1: the more recent, private and data-poor the topic, the more handicapped AI is. The 0-day is an ultimate weapon because it loads a lot of context; but if the vulnerability is just an easy CTF vuln, it'll still get solved fast.
Technique #2 — Context pollution
The idea
Flood the challenge with relevant noise that forces AI to load more context than it needs, and pushes it to explore false leads.
Reminder: the fuller the context, the more self-attention dilutes, and the more "lost in the middle" does its work. The truly useful info ends up drowned among 5000 lines of noise and the model, when it comes time to reason, no longer weighs it correctly. This is what's commonly called context rot.
How we pollute, in practice
- Multiply decorative vulnerabilities — real vulns that don't lead to the flag.
- Dead code that looks like active sinks — like a
do_query()function containing aneval()but never called. AI will spend time trying to reach it. - Misleading comments —
// TODO: fix this XSS before prodabove code that has no XSS at all. - Massive codebases — instead of a chall with 200 lines, put 5000. Most without interest.
- 0-days in "load the context" mode — a chall that forces you to read a 50 MB binary if you want to understand anything.
Example: the sink that isn't one
On a web chall, we put an endpoint:
@app.route("/admin/exec", methods=["POST"])
@require_admin
def admin_exec():
cmd = request.json.get("command")
# Legacy endpoint - kept for backward compatibility
# TODO: remove after migration #4218
output = subprocess.check_output(cmd, shell=True)
return jsonify({"output": output.decode()})Vulnerable, obvious, but unreachable: @require_admin validates a JWT signed with a key that isn't leaked anywhere else in the chall, and the only way to have an admin token is to solve the real chall (a logic error chain in session management, completely elsewhere).
The goal is to push the model to bypass the JWT (forgery, signature confusion, kid injection, etc.). The subprocess.check_output(cmd, shell=True) and the command mention in the request.json are salient patterns: these motifs have been massively labeled "dangerous" in training data (OWASP vulnerabilities, semgrep rules, public audits), and AI flags them by reflex. It forces it to invest its catalog of "classic" attacks on the JWT to reach this visible sink. Once these attacks are tried, it'll eventually browse other options and find the real sink leading to the flag — but in the meantime, we've burned tokens and context.
The participant who thinks for themselves, spots the real sink, and asks their model to focus on it is going to gain time over those who auto-solve challenges.
Small tip: add fake sinks that have a ton of known attacks, including bruteforce. It'll push the model to attempt bruteforce-based attacks that can be long, slow down players who only do AI, and incidentally generate tens of thousands of tokens of output that will push the real info into the "middle" of the context. And we hope to force the participant to dive into the challenge to correct course.
Takeaway #2: a clean sink in 200 clean lines gets flagged by any AI in 30 seconds. The same sink in 5000 lines with 3 well-built false leads also gets flagged but takes more time, context and tokens.
Limits
It's psychological defense in depth, not a real barrier. A better-designed AI (with better planning, or a user guiding intelligently) will eventually find it. But it rewards those who use it while asking themselves questions and is part of our objective.
Technique #3 — "Play the game of AI"
The idea
Identify topics where AI is technically ultra competent and abuse them. That is: it recognizes the vulnerability instantly, but it exploits it poorly because the method it was trained on for this type of challenge isn't the one that works in our setup. So we have to force it to deviate from its default reflex.
The textbook case: boolean blind SQLi
On one of our challs, we put an ultra classic SQLi:
$id = $_GET['id'];
$row = $db->query("SELECT * FROM articles WHERE id = $id LIMIT 1")->fetch();
if ($row) {
echo "Article exists";
} else {
echo "Article not found";
}A human who sees this immediately recognizes: boolean blind SQLi. You send conditions, you observe the output difference, you extract data bit by bit.
AI also spots the vulnerability instantly, and is over-trained to produce the exploitation script since it's a vuln present in almost ALL CTFs — the next-token probability space is ultra concentrated on known patterns (UNION-based, sqlmap, classic payload).
Except the trick is that we set up a dead-simple rate-limit on the application that prevented dumb-and-dirty bruteforce.
As we said earlier, the machine doesn't have the same relationship to time as we do. It provides an exploit script that works in the absolute. And it manages quite quickly to obtain the first results — that confirms its finding. So it's convinced of the correctness of its payload, and this confirmation, being among the latest tokens in its context, will weigh heavily on what follows (recency bias): it will continue pushing in the same direction.
Except for that challenge, without optimization, it took 30 hours to extract the flag. With basic optimizations, in less than 40 minutes, the flag drops.
Yet no team solved this challenge, not a single person out of 130 participants. Because you almost had to "prompt inject" the model to force it to explore another way to solve it.
The model is over-trained on this attack, knows how to spit out the resolution script instantly, and has very quickly confirmed that the script "works". So if we don't give it a good reason to adapt or consider an alternative, it will keep confirming this is the right way to do it.
This forces the user to lean into the challenge, understand it, and better guide their model with their expertise.
Except what was happening was that players were losing patience, sometimes thinking the model was hallucinating, and starting over from a fresh context. For us it's all upside: new exploration, we burn tokens!
Takeaway #3: spot techniques where AI is trained but where its "default" output is suboptimal. The user will need to know the topic to correct it, and that's exactly what we want.
Technique #4 — What separates the human from the machine: time
The idea
This technique was often combined with others and consists of waiting. Here we play on the user's patience and hope they will reset, start over from scratch because they think AI is doing nonsense or has crashed.
So: we design challs where efficient resolution requires letting it run.
Careful, the idea isn't to make guessy/bruteforce challs but ones that remain interesting to solve.
Exploitable mechanics
| Mechanic | Effect |
|---|---|
| Strong rate limit on a key endpoint | Forces waiting between requests |
| Slow backend by design (server-side sleep) | Each attempt costs real time |
| Account lock after N attempts | Forces patience |
| Cron job that only runs every 10 min | You wait for it or work around it |
| Dependency between challs with imposed delays | Chall B requires an event triggered by A 5 min earlier |
Example: the time-based SQLi that forces waiting
Let's revisit our SQLi from technique 3 and assume AI found the right optimization to solve the challenge in around twenty minutes. For a human, twenty minutes is long. And if the user hasn't understood the challenge, they'll think AI is hallucinating/crashing and start from scratch — so once again rebuild their context, and burn tokens.
So it forces the user to understand the challenge to grasp that the flag will only show up in 20 minutes. On a 12-hour competition, that's largely acceptable.
We can also add small optimizations to "pollute" the context. For example we return a 429 error if you exceed the request count, with a cooldown that progressively lengthens (1s, 2s, 4s, 8s...).
To extract a 32-character password in SHA256 → 64 hex chars → ~256 bits → ~256 requests in binary search. At 1 req / 2s = ~9 minutes of runtime minimum.
An agentic AI piloting this: at each request, it receives a tool output it puts back in its context. 256 requests × ~300 tokens on average (request + response + retry-after + model's internal narration) = ~77k tokens burned just for runtime. By playing on the verbosity of 429 responses (a chunky body, custom headers), you can push up to 100-150k tokens and saturate the window before getting the full password. And along the way, the initial instruction (the chall description) drifts into the "middle" of the context as tool outputs accumulate — exactly the scenario where lost in the middle degrades the model's reasoning.
Takeaway #4: time is one of the resources where its value is "the most different" between a model and a human because of our emotions. The more a solution is spread out in time, the more it forces the user to understand because it generates frustration.
Watch out for the trap
You have to dose it. If the entire CTF requires waiting 10 min, humans will leave too.
Technique #5 — "Prompt injection" via the description
The idea
Put in the chall description something deliberately misleading or noisy, to push AI in a wrong direction. It's the direct application of the primacy effect: the description is the very first signal AI receives, and it's the one that will weigh most heavily on all the reasoning that follows.
I didn't think it would be this effective.
How AI handles a description
When a user tells Claude "here's the chall brief, help me", the description lands at the top of the context, right after the system prompt. It's the most powerful position in terms of attention weighting. AI will look there for keywords (technique names, tools, references to known CVEs) and orient its resolution strategy around these anchors. The more salient the keywords, the more AI will hallucinate matching leads.
If the description contains a reference to sudo, AI will spend 5 minutes investigating sudo privesc, even if the chall has nothing to do with it. If it mentions "database", it'll look for SQLi, SQLite files, MySQL credentials — even if there's no database on the machine.
Concrete example
One of our system challs mentioned a database in its description.
The solution was almost to do a sudo su with just a small trick on PAM, really nothing complicated.
Except in the description, we mentioned that this system was the backup of an old website with a corrupted DB (or something like that).
Players copy the description + connection URL all at once (usually without even taking the category) and wait.
For this challenge, everyone was running in circles on the famous website. Whereas in the challenge there was nothing: it was really a base Debian with the vuln. No Apache, Nginx, MySQL service, no SQLite file. And I was getting AI-generated messages asking me to give DB access. When it had nothing to do with it — the challenge was IMMENSELY easy compared to others that got pwn'd in a few dozen minutes.
Result: 0 SOLVES
It's the perfect illustration of the biases mentioned earlier. AI anchors its strategy on the initial description (primacy) and on the last tool outputs (recency). In the middle, it could nevertheless have seen 100 times that the machine is an empty Debian — but this info, drowned between the misleading description at the top and the recent tool outputs at the bottom, falls right into the lost in the middle zone. The model keeps reasoning "there's a DB somewhere" even when its own ps aux, netstat -tulnp, find / -name "*.db" shouts the contrary at it.
That's also why agents that periodically summarize context ("compaction", rolling summary) can partially bypass this technique — they bring useful info from the middle to the bottom. But in April 2026, in the majority of user workflows (Claude.ai web, ChatGPT, Cursor in chat mode), this remains exploitable.
Takeaway #5: the chall description is not neutral. It's a text input AI will process, so it can be designed to orient (or disorient). Use sparingly: too much noise and the event becomes guessy rather than technical.
On the organization side — a quick word
In 2026, designing AI-resistant challenges isn't enough. You also need the event to make people want to play with or without the leaderboard. Otherwise people open Claude and farm the solves.
Several mechanics we put in place that worked well:
- Bounty mode — a few challs with a cash prize for the first X solves. It concentrates attention on the hard challs, those we couldn't solve with AI.
- Badge — a physical badge handed over in person. Small emotional reward.
- Sub-rankings — parallel rankings (e.g.: category with and without AI, etc.) so everyone can play in the arena that suits them best.
- Side quests — get as many badges as possible, trade points for items in a shop, etc.
The full organizational details will be in the Hack'In 5th edition retrospective post.
Did it work?
We had two representative groups we monitored during the competition:
- Group NO-AI: teams that voluntarily forbid AI (28 teams)
- Group AI-LOVER: teams that used AI (7 teams)
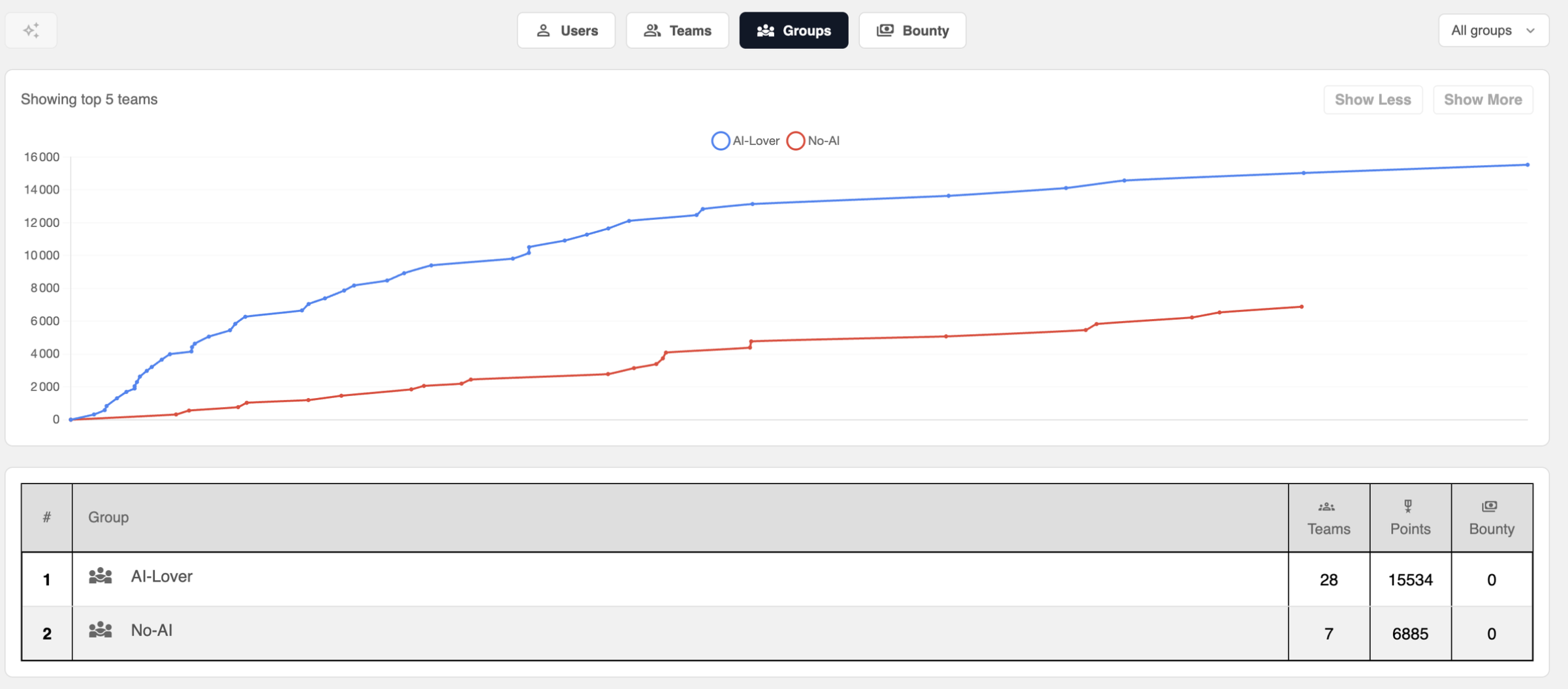
Here's the resolution speed:
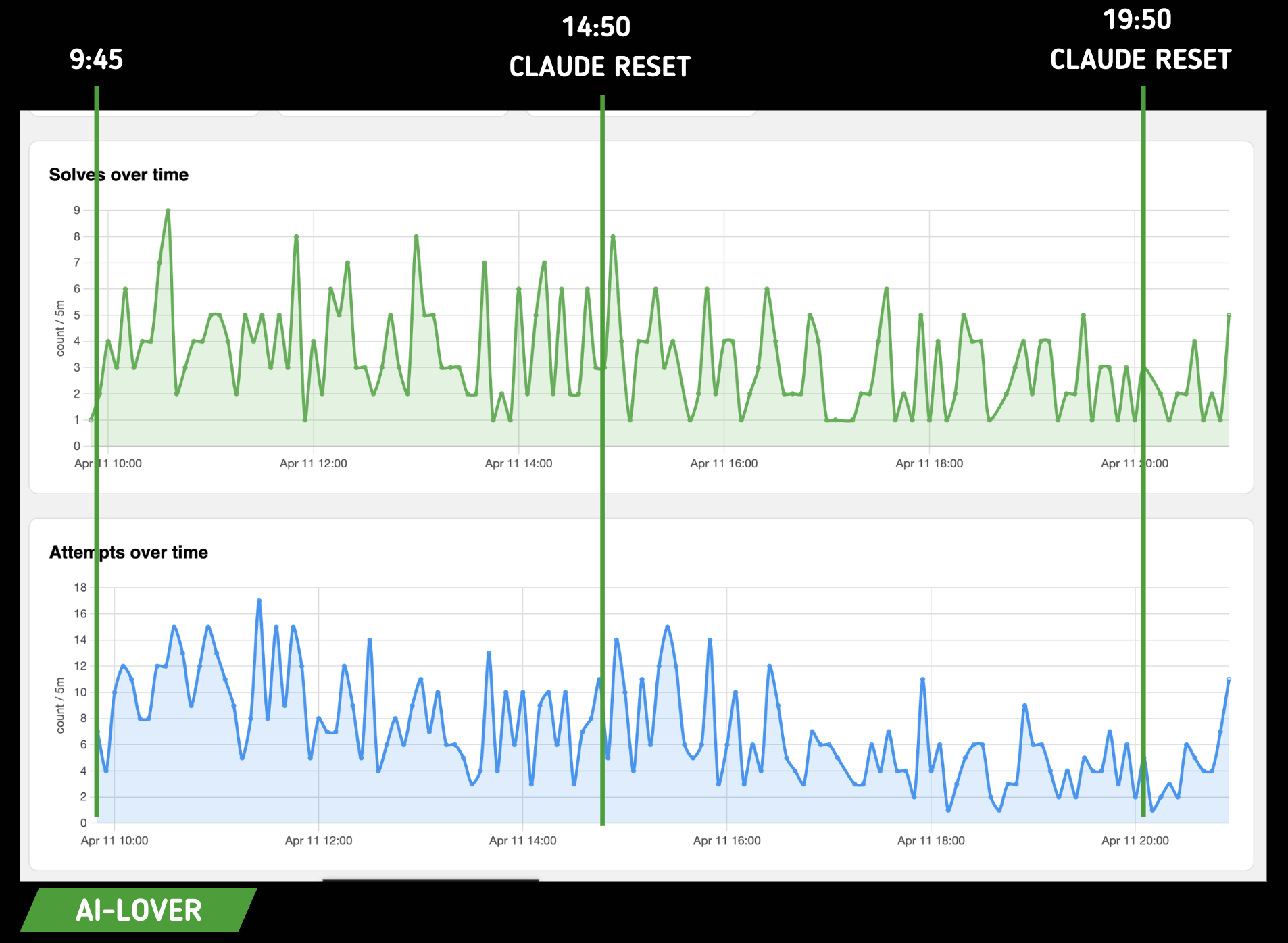
For the AI team:
For the NO-AI team:
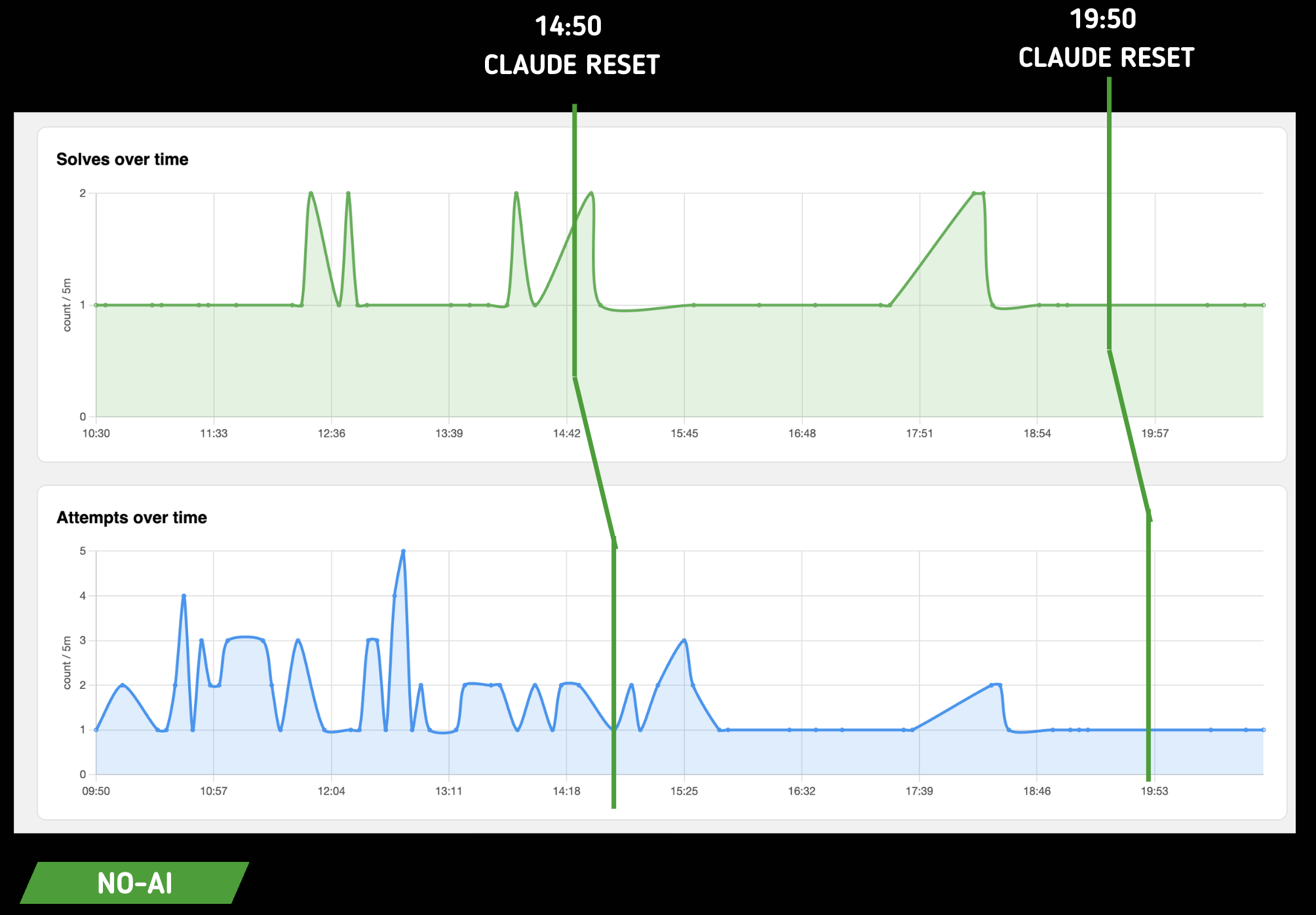
Here we can see clearly that challenge resolution isn't indexed on the Claude token reset. For us that's good news: it means there was no direct, or in any case obvious, correlation between token availability and ease of resolution.
However we noticed a difference in the way of flagging.
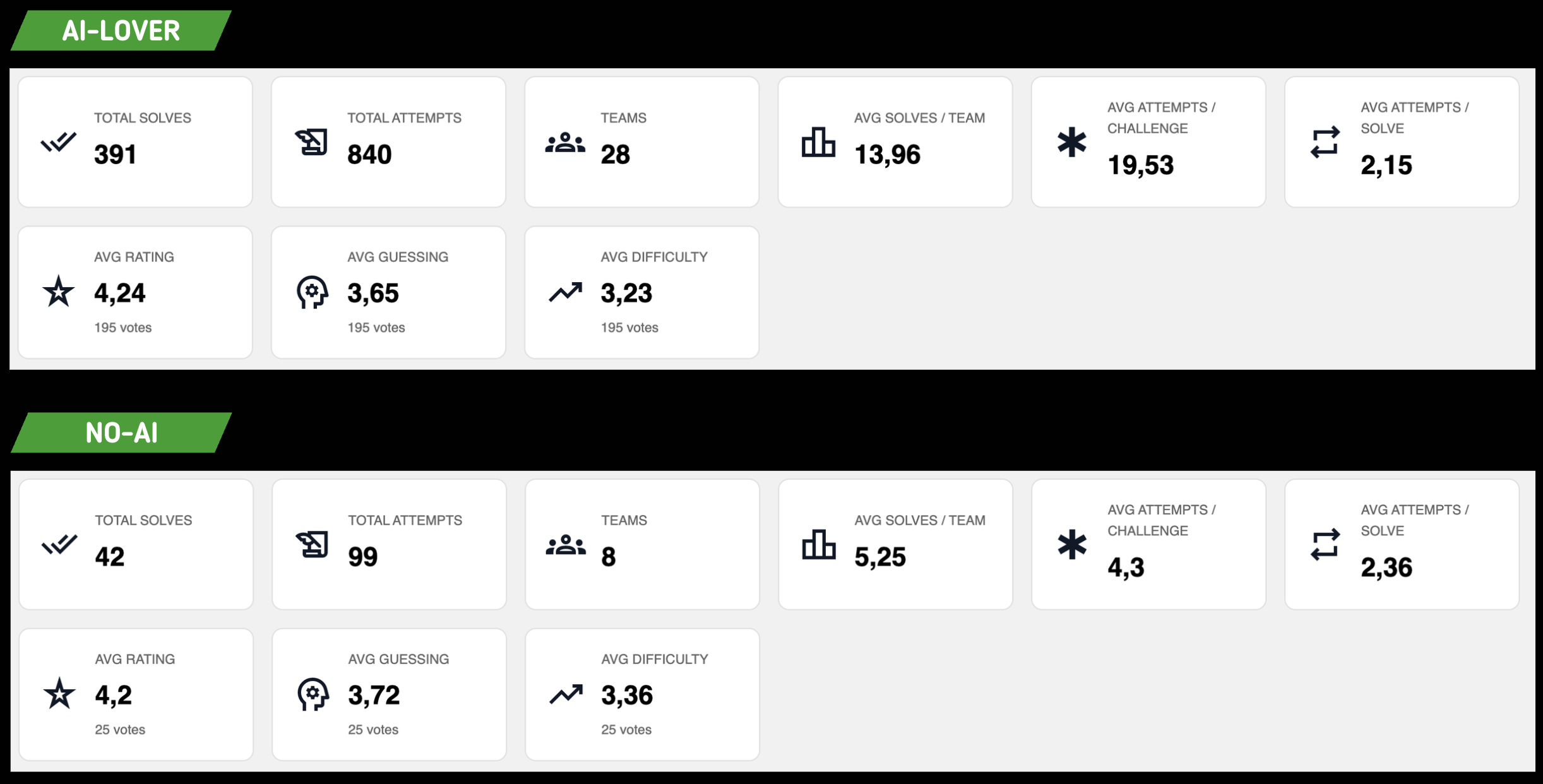
First we see that the average challenge resolution for AI teams is 13.96 out of 48 challenges, i.e. 29.08% of the challenges, which is a HUGE victory for us.
We were afraid our CTF would get folded in an hour, and even after 12h the resolution rate stayed low.
Here on the top 13 the number of challenges solved
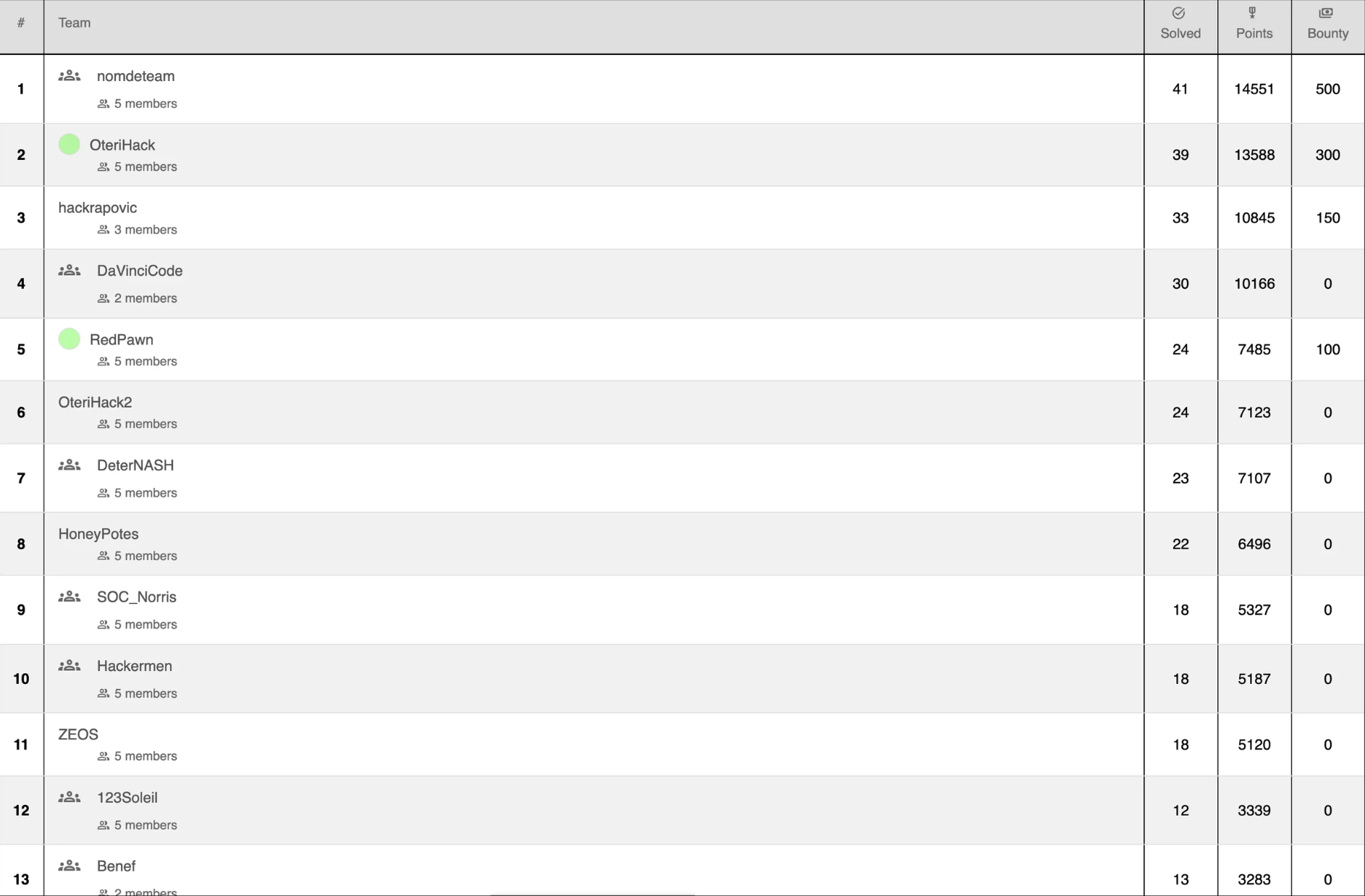
We see that as early as 5th place we barely reach 50% resolution.
However, the number of solves per challenge is absolutely useless if we can't correlate it to overall quality. Here we got a score of 4.2 out of 5 across both groups. This means that players, in addition to finding the challenges interesting, took as much pleasure solving them WITH or WITHOUT AI, which is our biggest victory 😎.
Fun fact: the AI group tended to find the challenges a bit more guessy and easier than the users without AI 🤡. Unfortunately the number of votes doesn't allow a statistically solid comparison, but that's the micro-trend that emerges. Make of it what you will.
We also see that the average number of attempts per challenge is 4x higher on AI side challenges. Yet, when a team actually solves a challenge, it takes them an almost equal number of attempts to get there, AI or not.
This means that overall, players who use AI tend to enter hallucinated flags without verifying. We had defined an attempt limit per challenge on our side to not punish this effect too much.
Direct feedback
During the CTF we went around all participants to ask individually what they thought of the competition and whether AI ruined the fun of flagging. We polled exactly 119 people.
- 118 out of 119 answered that the challenges were interesting to solve even with AI and that overall they were surprised by such resistance.
- 1 out of 119 told us that yes it does resist quite a bit, but ultimately it'll only ever be a question of tokens and you just need to consume more of them, and so it didn't make us more resistant than any other competition.
In the same way that our solves are worth nothing without a score on the challenges, the score is worth nothing without direct feedback. In absolute terms they were all super positive, but a picture's worth a thousand words, so I'll leave you with the feedback from the team that came in second and the one that came in sixth, both used to CTFs.
